들어가며
딜리셔스 정보검색파트에서는 Elasticsearch를 활용하여 검색서비스를 개발하고 있습니다.
검색서비스를 위해서는 크게 두 가지 사전 작업이 필요합니다.
- Database에 있는 데이터를 검색엔진에 색인하는 과정
- 색인된 Document를 안전하게 Serving 하는 과정
이번 포스트에서는 첫 번째에 해당하는 ‘색인 과정’에 대한 이야기를 나누고자 합니다. 기존 딜리셔스 검색엔진의 색인 처리 프로세스를 간략히 소개하고, 이를 개선하기 위해 저희가 고민했던 과정을 공유하겠습니다.
목차
- Indexing History
- What’s Kafka?
- What’s ECK?
- Tiqui-taca Project
- Result
- Future
1) Indexing History
옛날 옛적 신상마켓 검색엔진의 색인 과정을 살펴보고 어떻게 변화해 왔는지, 그리고 우리는 왜 NRTI를 하려고 했는지를 조금 이해해보는 시간을 갖고자 합니다.
1-1) 초기 ~ 2020.03
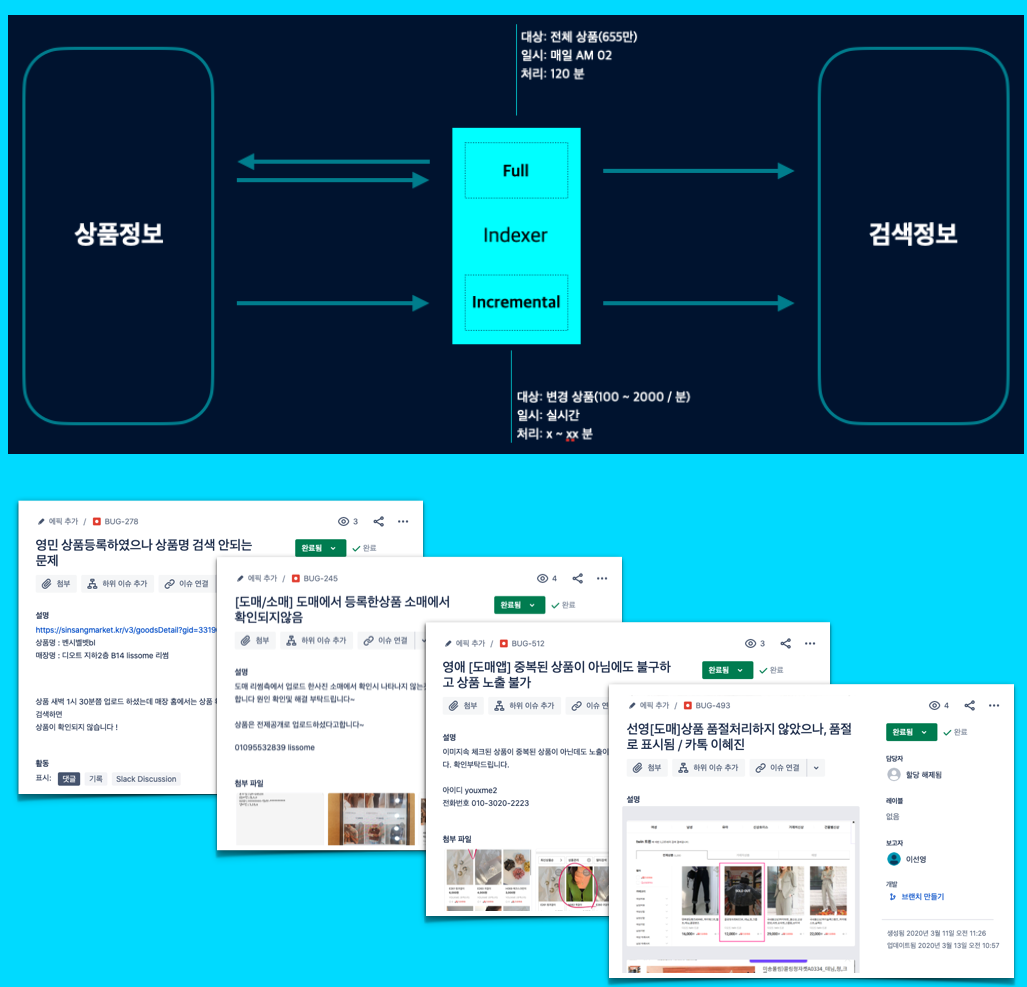
- 처리방식
- 전체색인 : 색인기 (매일 새벽에 수행 - 700만개 2~3시간 소요)
- 증분색인 : 분당 100 ~ 2000 개 수행
- 문제점
- 전체색인 동작 시 증분색인 데이터 누락(신규상품, 변경정보 누락)
- 증분색인의 늦은 처리시간으로 상품 노출되지 못하는 경우 발생
1-2) 2020.04 ~ 2021.03 WALL-E 프로젝트

- 문제해결
- 기존 시스템의 문제점인 상품 정보 누락 사라짐
- 증분색인의 속도 향상으로 상품 노출 향상됨
- 처리방식
- Batch 에서 전체색인, 증분색인 모두 담당
- 증분색인 분당 500건씩 처리(처리속도 10~20초)
- 문제점
- 단일 Instance 에서 수행되어 안전하지 못함
- 증분색인 시 여전히 느린 처리 시간
- 단일 Application 으로 개발되어 점점 비대해지는 코드(갈수록 개발이 힘들어짐)
1-3) 2021.04 ~ 2022.10 WHALE 프로젝트
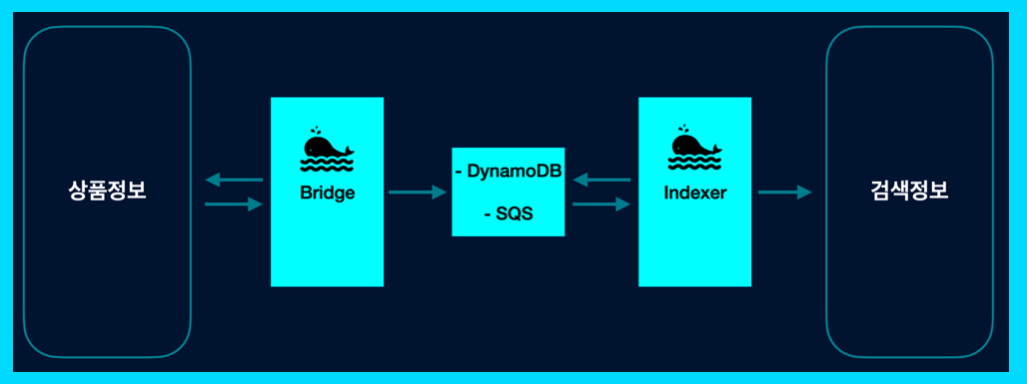
- 문제해결
- 단일 Instance를 벗어나 안전성이 보장됨
- Message 방식으로 증분색인 속도가 약간 향상됨
- 역할이 잘 분산되어 로직이 단순화됨
- 처리방식
- Bridge, Indexer 등 역할 분담
- dynamoDB를 중간 저장소로 활용하여 데이터 정합성을 높힘
- SQS, Trigger 활용하여 Message 처리
- 문제점
- 많은 데이터, 많은 조인을 1분마다 쿼리하여 DB 부하 높아짐
- dynamoDB 사용으로 인한 비용증가
- SQS 에서 처리되지 못한 Message가 좀비처럼 동작됨
- Elasticsearch 관리에 대한 어려움으로 운영이슈 증가
상품 데이터를 색인하는 프로세스는 위와 같이 개선되어 왔습니다. 하지만 여전히 ‘빠르고 안전하게 상품 데이터를 노출한다’라는 목적에는 부족한 느낌입니다. 이러한 한계를 해결하기 위해 두 가지 목표를 설정했습니다.
- 안정적으로 검색엔진을 운영할 수 있는 구조
- 빠르게 데이터를 색인할 수 있는 구조
2) What’s KAFKA

저희는 Message 방식으로 이벤트를 처리하기 위해 Apache Kafka를 도입하기로 하였습니다. 도입 근거에 대한 설명에 앞서 몇 가지 중요한 용어와 개념을 살펴보겠습니다.
- Topic : pub/sub message
- Partition : Topic 분산처리
- Producer : message 게시
- Consumer : Message 구독
2-1) Kafka Consumer Group
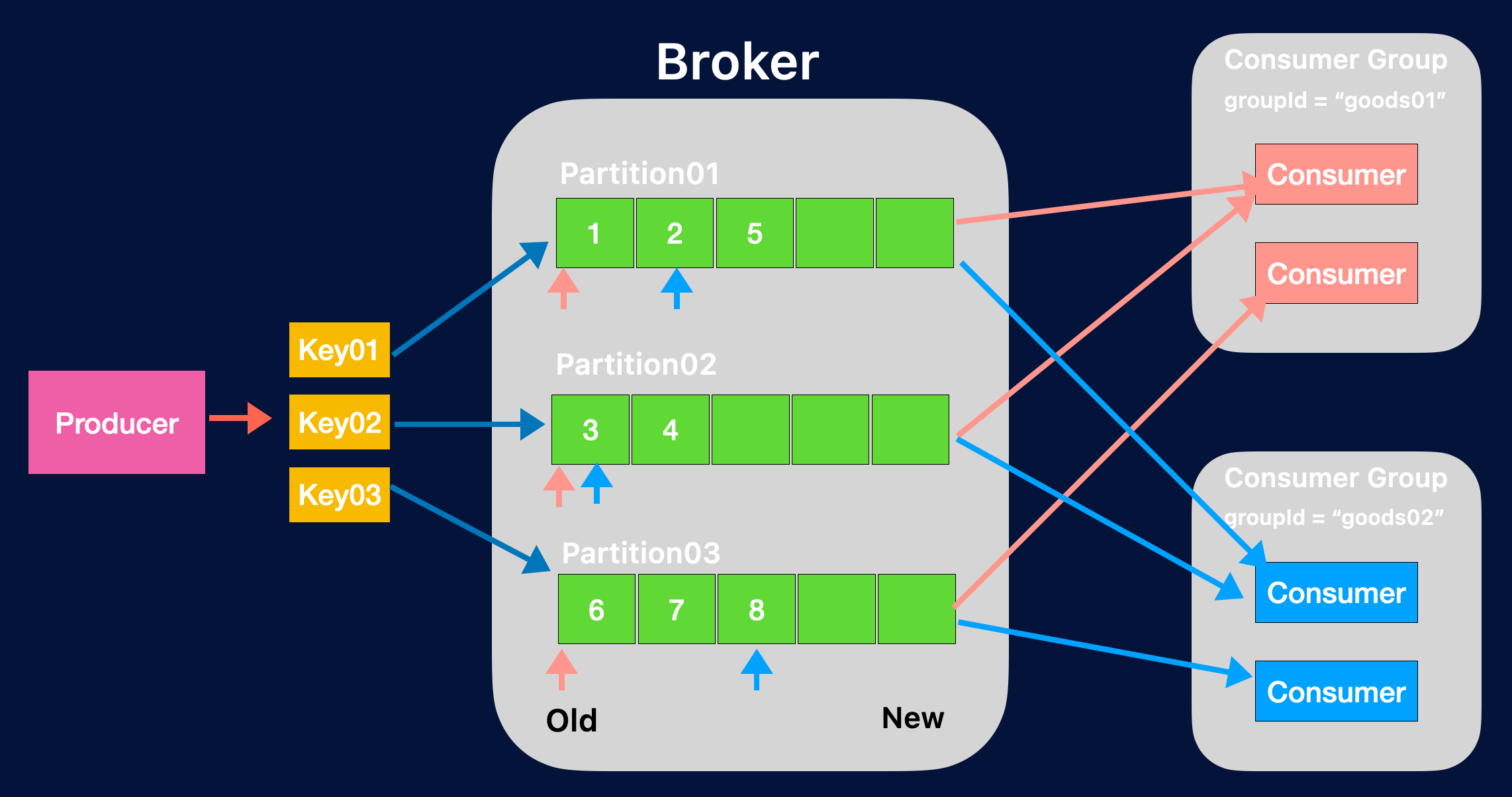
위의 그림처럼 Producer에서 Key 별로 Partition을 분배할 수 있으며, 이때의 장점은 데이터의 정합성을 유지할 수 있다는 점입니다.
예를 들면, 특정 사용자 그룹별로 Key를 묶어서 Partitioning을 하게 되면 Consumer Gorup을 지정하여 Consume 할 수 있습니다. 그림에서 볼 수 있듯이 groupId = “goods01”의 Consumer가 각 Partition에 구독을 하게 됩니다. 이때 새로운 gorupId = “goods02”가 붙게 되면 새롭게 Partition에 구독할 수 있어 정합성을 유지할 수 있습니다.
이때의 장점은 group 별로 offset이 다르게 동작하게 되어서 각자 데이터 처리를 할 수 있다는 점입니다. 하지만 한 가지 주의점이 있습니다.
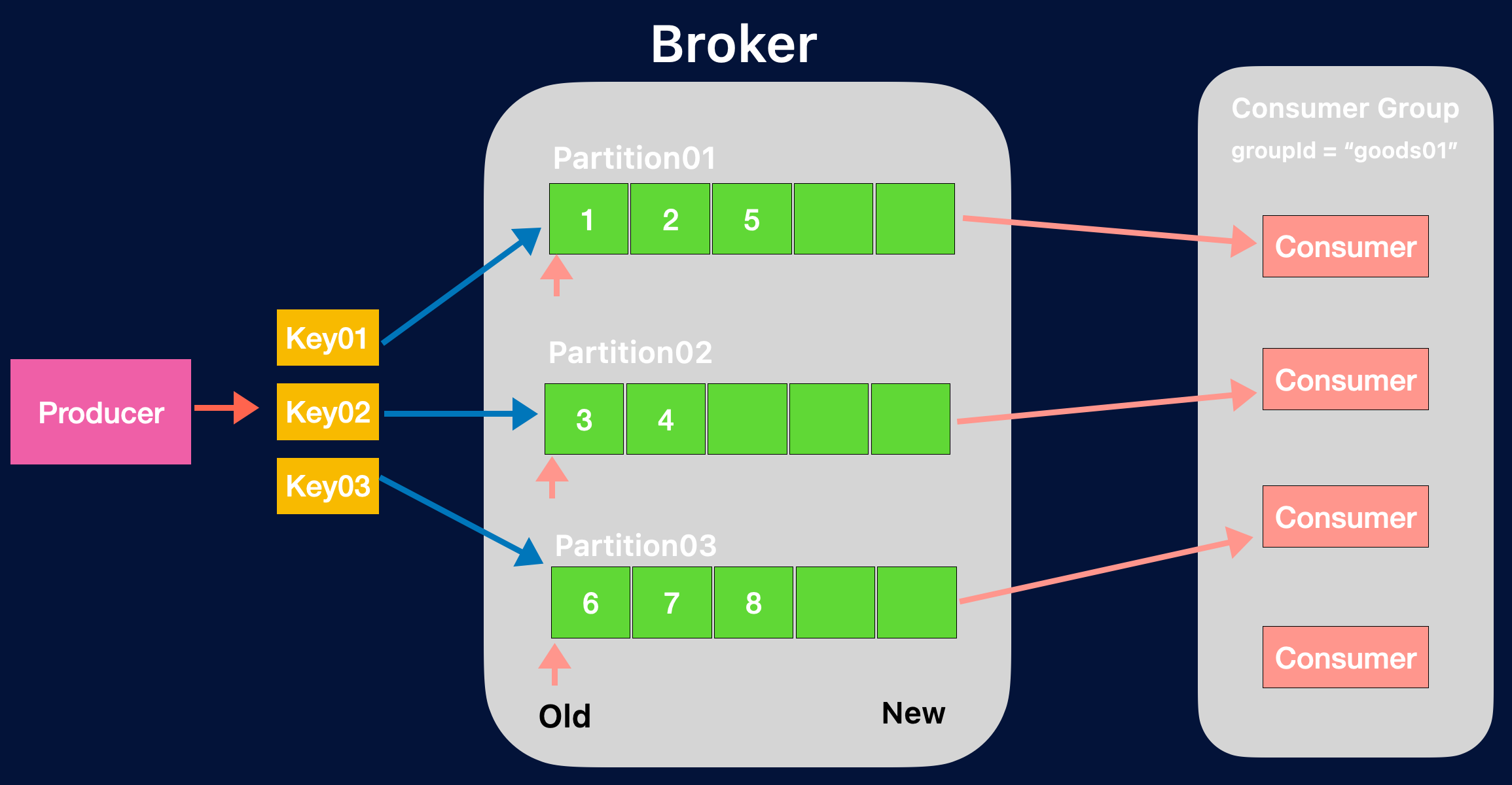
Partition = Consumer Group은 1:1로 구성하는 게 유리합니다. 그림에서 보듯이 Partition = 3, Consumer Gorup = 4 로 구성하게된다면 Consumer 1개가 IDLE상태에 빠져서 불필요한 리소스 낭비가 발생하기 때문입니다.
2-2) Kafka Connectors
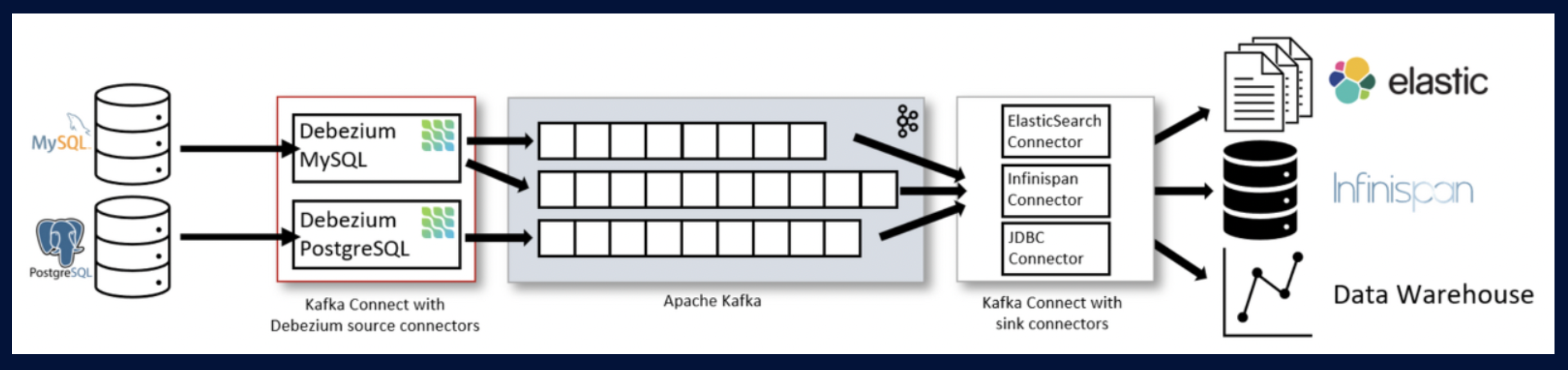
Kafka Connectors는 Producer/Consumer 파이프라인의 반복을 없앴다고 생각하면 됩니다. Connector를 적절하게 설정하면 데이터 구독/발행 시 Producer/Consumer를 개발하지 않고 활용할 수 있습니다.
저희는 Debezium Connector를 사용하기로 하였습니다.
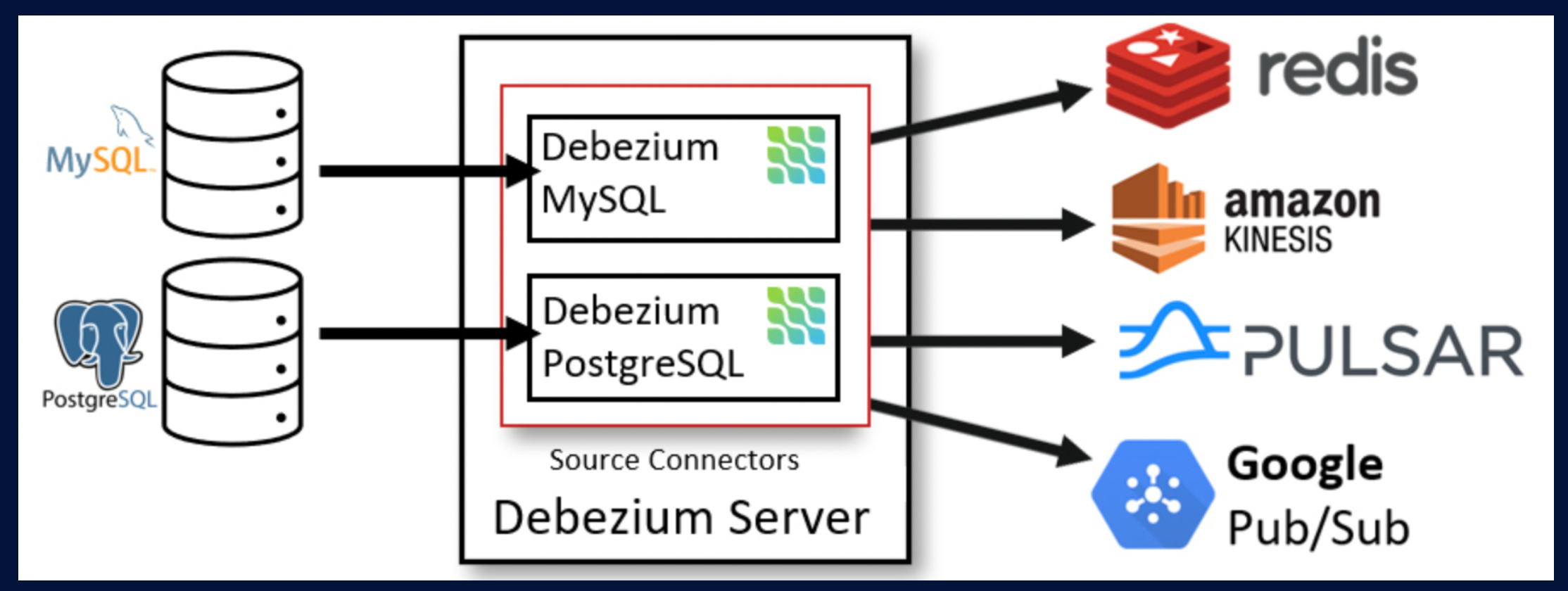
Debezium은 CDC(Changed Data Capture)를 편하게 해주는 도구입니다. MongoDB, MySQL, PostgreSQL, SQL Server 등 다양하게 선택할 수 있으며, MySQL의 bin Log를 읽어들여서 Topic을 발행하는 역할을 합니다.
저희는 상품 데이터의 변경사항(등록, 수정, 삭제)에 대한 변경상태를 Debezium을 통해 Topic Message를 만들고 Consumer를 통해 해당 상품 데이터를 검색엔진에 색인하는 로직을 구성하였습니다.
3) What’s ECK
ECK는 Eclastic Cloud on Kubernetes의 줄임말로, k8s(Kubernetes) 환경에서 Elasticsearch 검색엔진을 좀 더 편하게 구성할 수 있게 도와줍니다. 이 외에도 다양한 기능을 추가로 제공하여 더 안전하게 검색엔진을 운영할 수 있다고 판단하였습니다.

위 그림에 표시되어 있듯이, 저희에게 필요한 기능을 대부분 제공하여 채택했습니다.
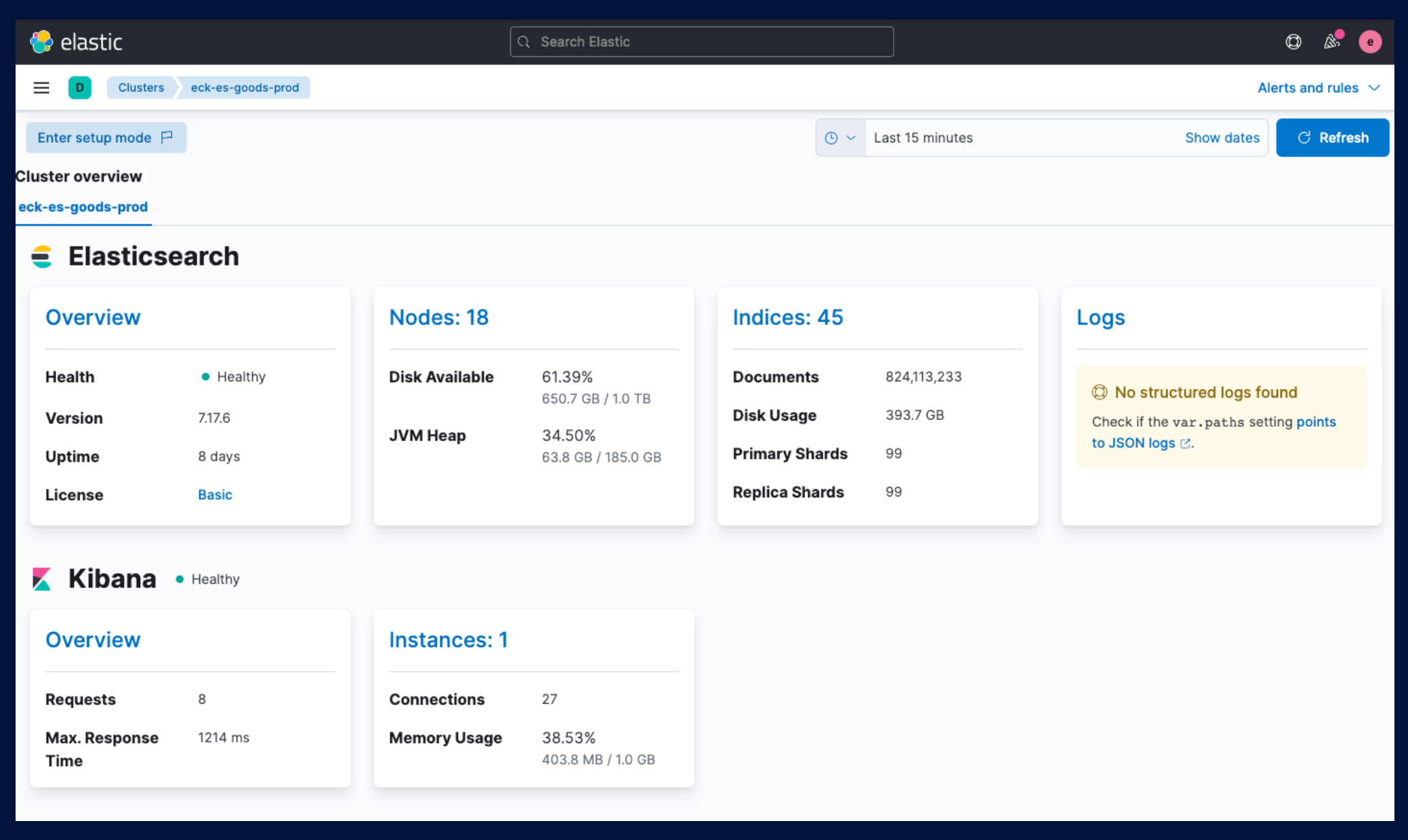
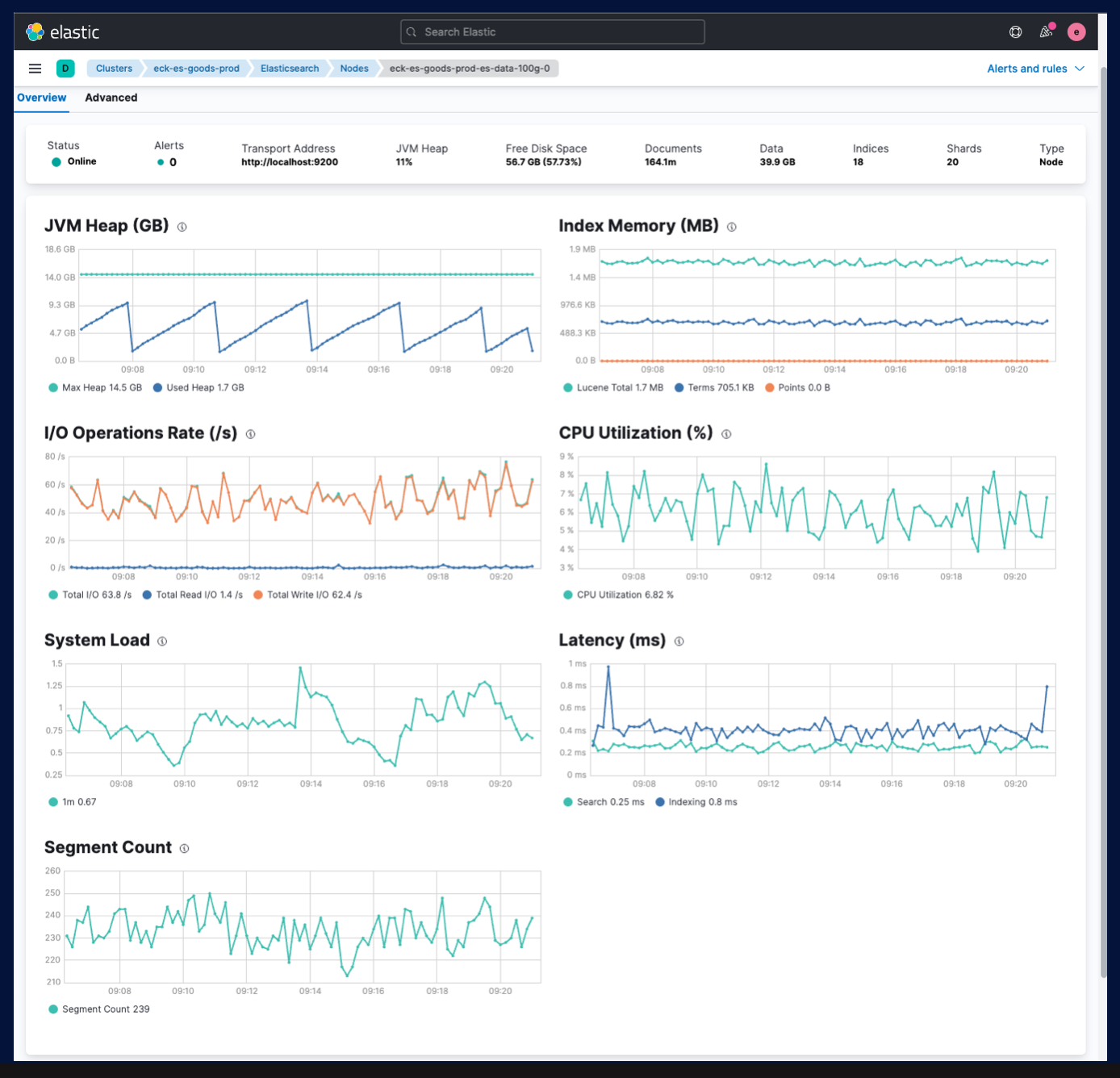
기본적으로 fileBeat, MetricBeat가 설치되어 모니터링도 훨씬 강화할 수 있습니다.
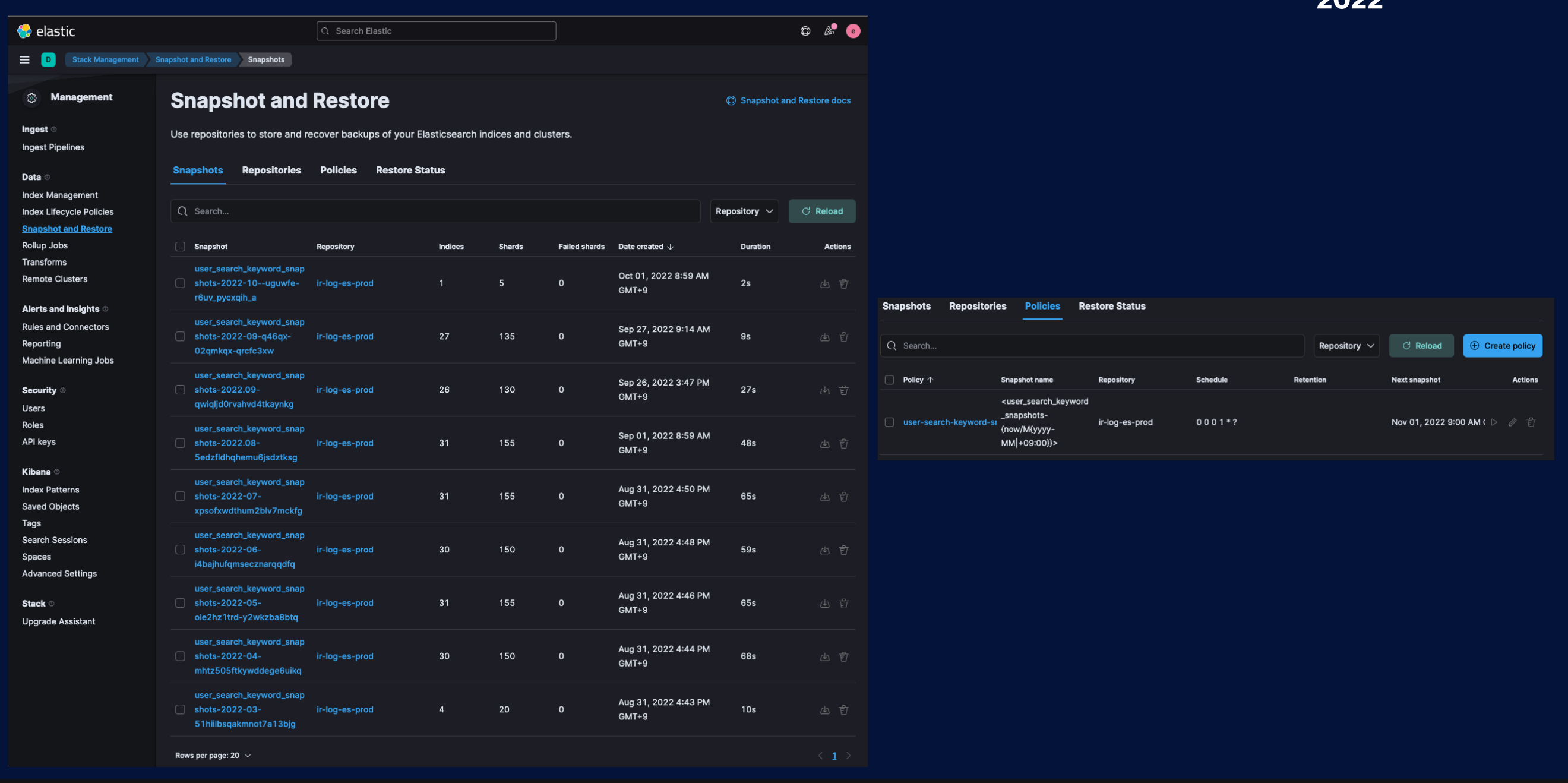
또 중요한 점은 Snapshot의 Backup/Restore 기능도 훌륭하다는 것입니다. 인덱스를 Snapshot 만들고 S3 Bucket을 연결해주면 S3에 바로 Bakcup이 가능합니다. Policies를 구성하여 주기적인 Backup 설정도 가능하며 Restore하여 데이터를 복구할 수 있습니다. 유사시에 주기적인 백업을 통해 데이터를 빨리 복구하여 장애 상황에 조금 더 빠르게 대응할 수 있습니다.
4) Tiqui-taca Project
이렇게 저희는 여러 기술에 대한 research와 prototype test를 통해 최적의 아키텍쳐를 구성하였고 성공적으로 사용 서비스에 적용했습니다. 제일 중요한 포인트는 Kafka를 통한 Message 처리이며, ECK를 통한 안정적인 검색엔진 운영이었습니다. 앞서 저희가 목표로 삼았던 부분을 적용한 기술과 연결해보면 아래와 같습니다.
- 안정적으로 검색엔진을 운영할 수 있는 구조 -> ECK를 통해 해결
- 빠르게 데이터를 색인할 수 있는 구조 -> KAFKA를 통해 해결
이렇게 해서 아주 Simple한 아키텍쳐가 만들어 졌습니다.
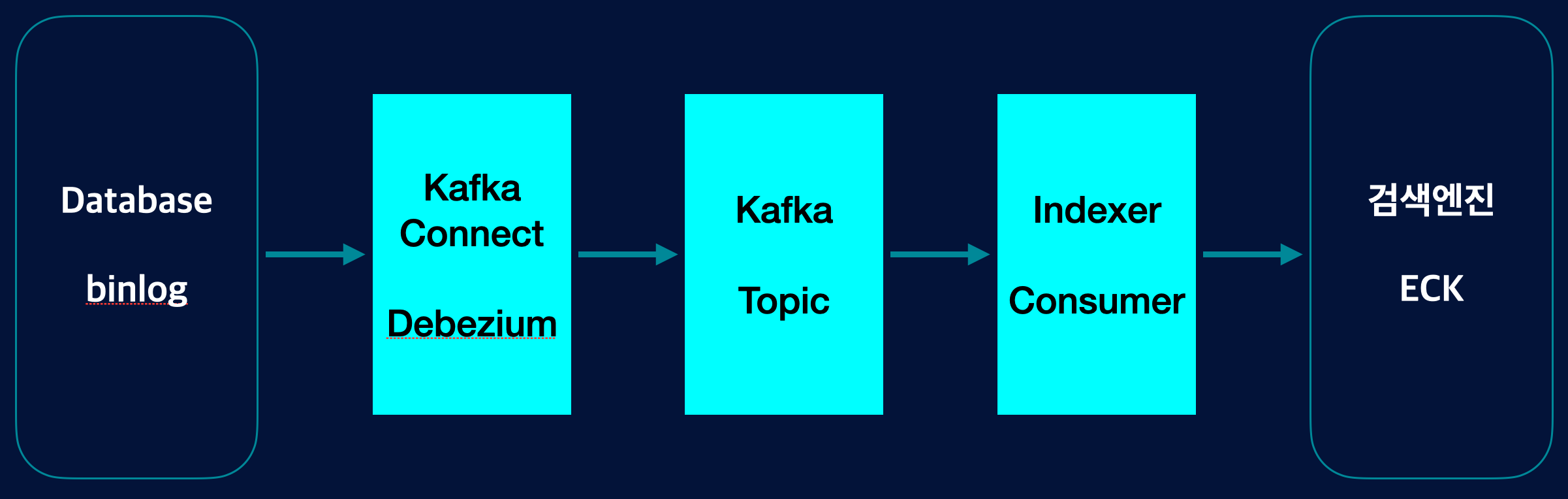
그림에서 볼 수 있듯이 Debezium을 통해 상품 데이터 Topic 발행을 하고 Indexer Consumer Application을 개발하여 검색엔진에 색인하는 로직을 넣었습니다. 저희가 개발한 Application은 Indexer 프로젝트 1개 였습니다. Kafka Connect 관련한 설정은 Kafka UI framework를 사용해서 구성해 놓았습니다.
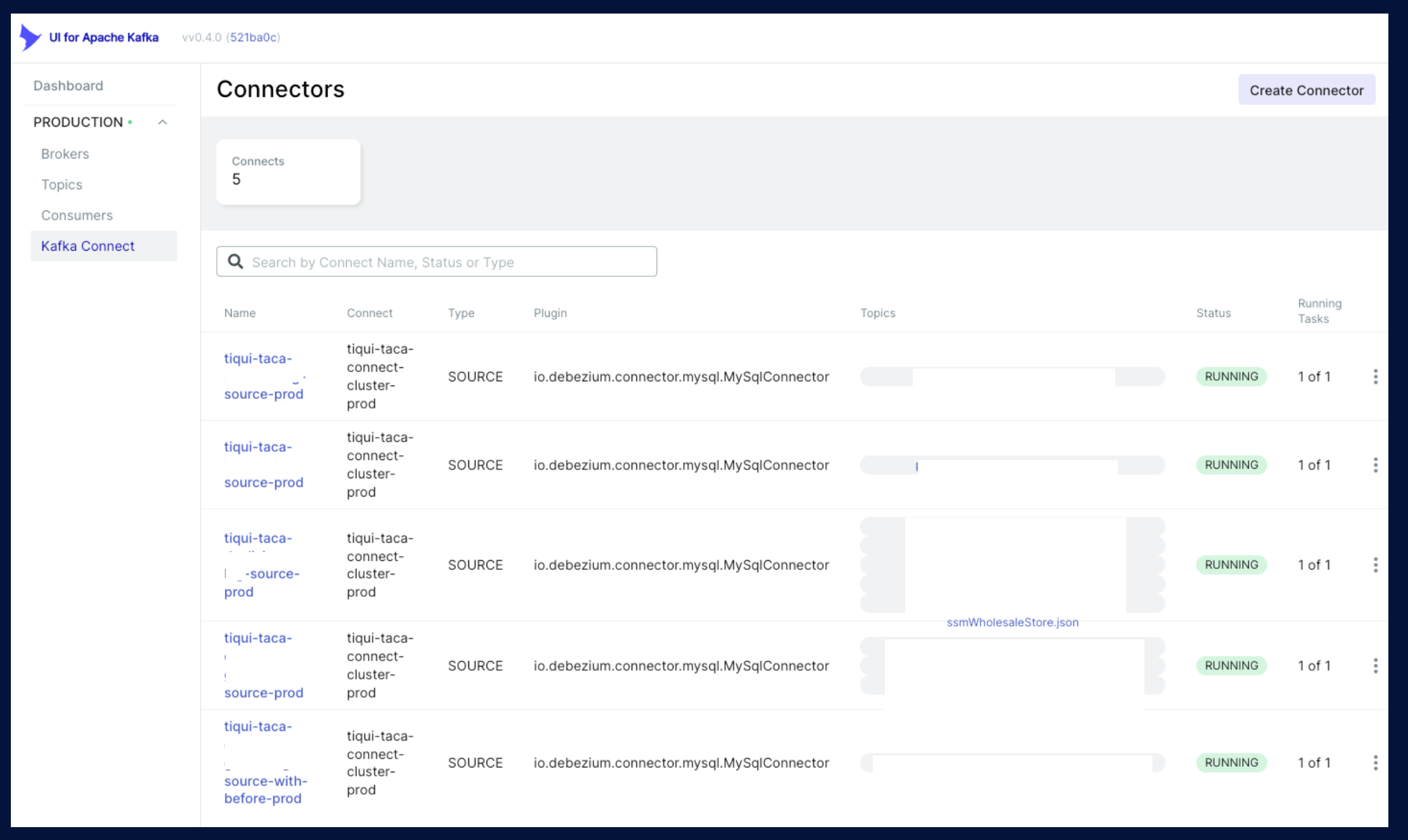
Connector가 설정되어있는 모습입니다. 설정을 조금 더 살펴보면,
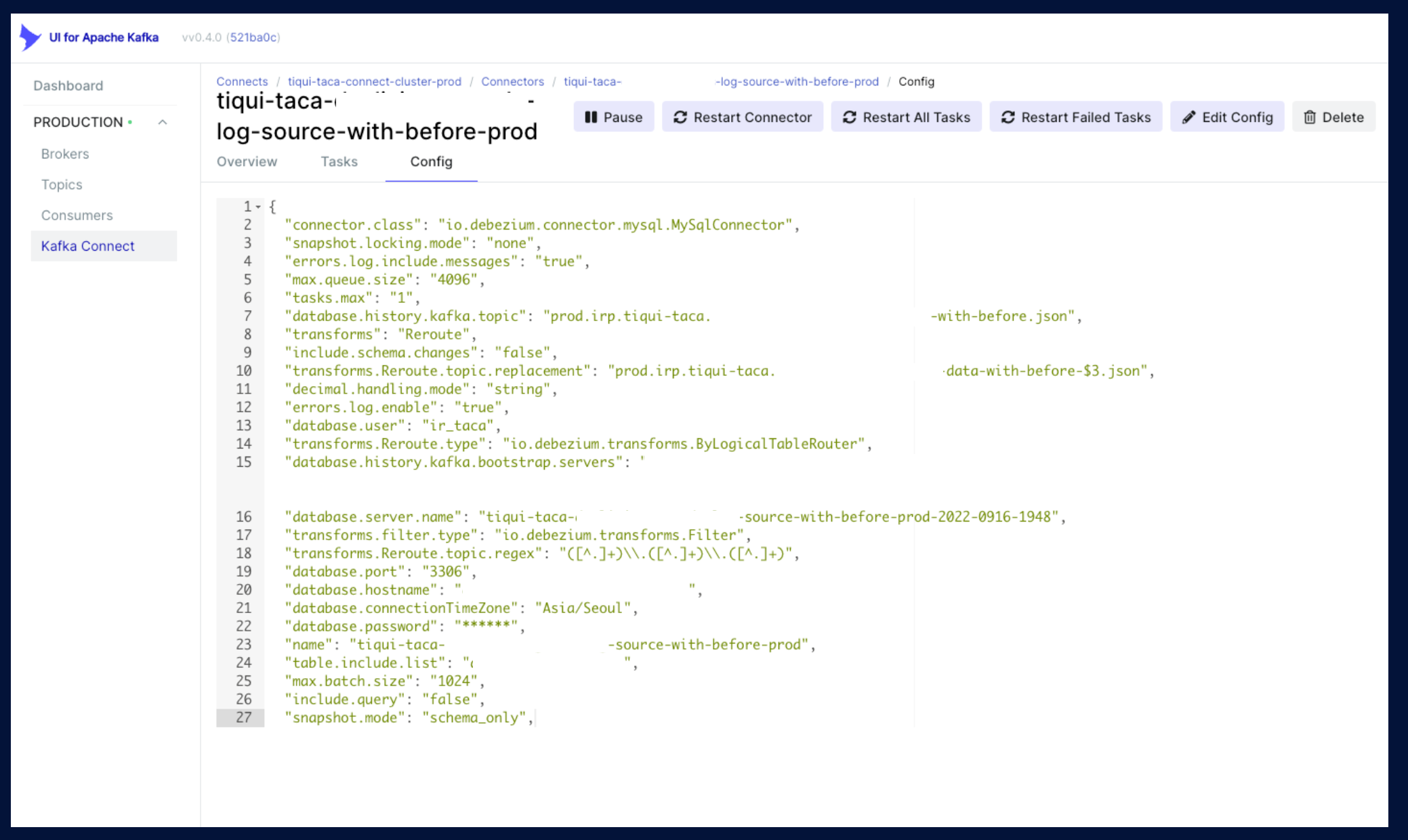
Database를 지정하고, Topic naming을 설정하고 여러 가지 옵션을 설정하여 저희가 원하는 Topic 을 구성할 수 있습니다. 이렇게 발행한 Topic을 살펴보면
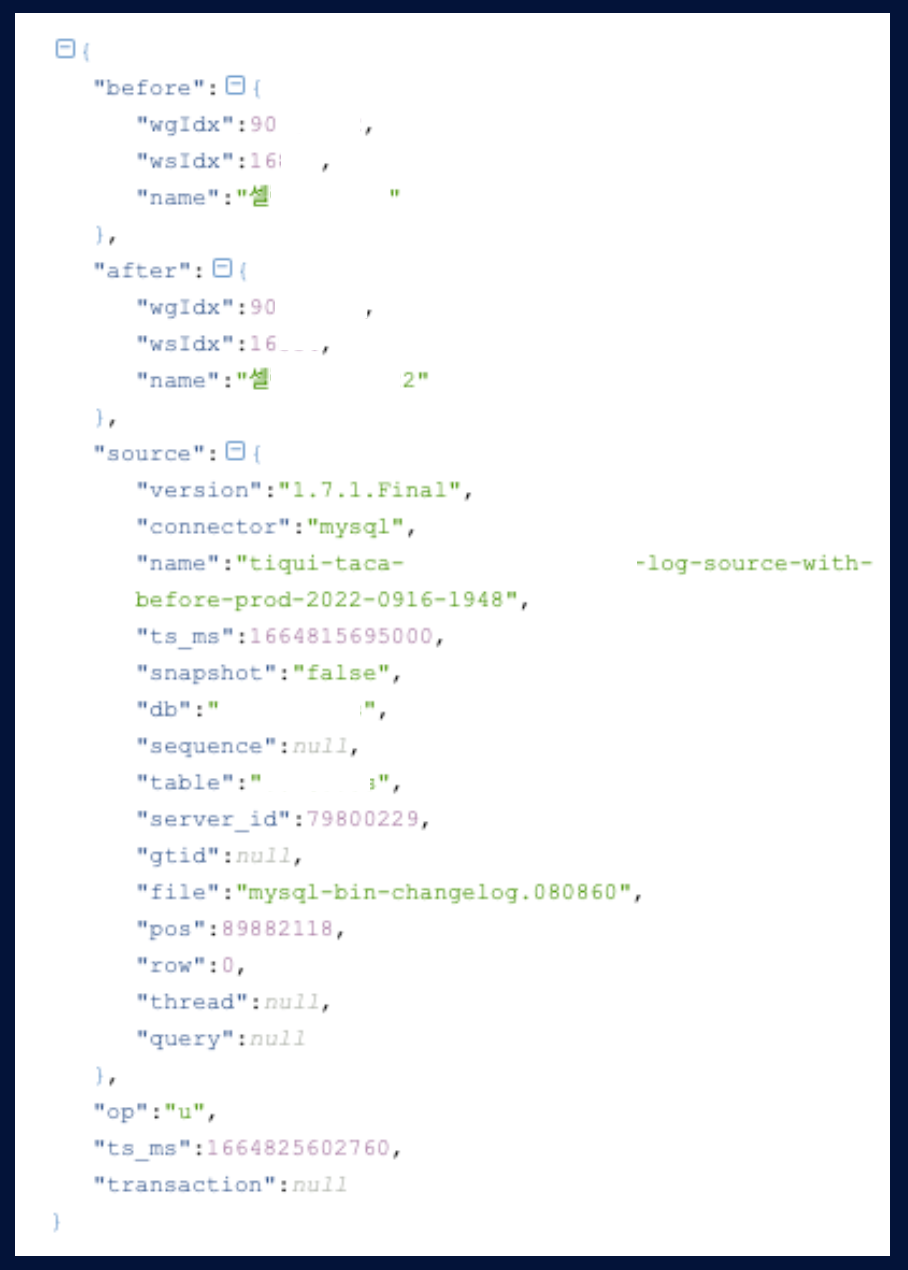
위 그림처럼 before, after로 구성하여 어떤 변경사항이 있었는지 비교가 가능합니다. op 키워드를 통해 create, update, delete 등 해당 데이터가 어떤 것인지 직관적으로 알 수 있습니다. 이렇게 발행한 Topic은 Partition으로 나뉘어서 들어가게 됩니다.
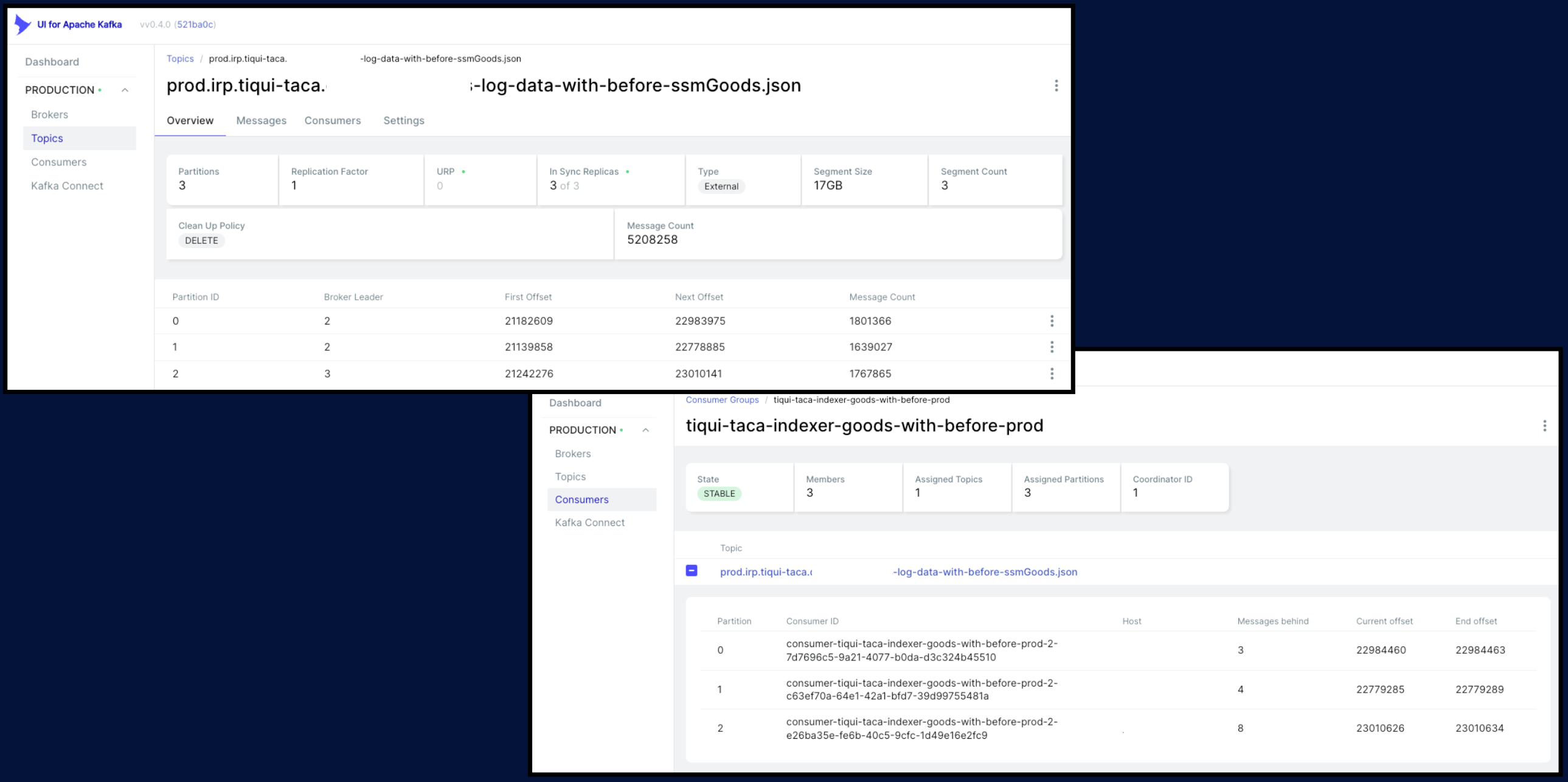
위 그림처럼 Partition을 3개로 나누었고, Indexer Consumer Application도 3대로 구성하여 1:1 매칭이 되도록 구성하였습니다. indexer Consumer Application의 구성을 살짝 살펴보면
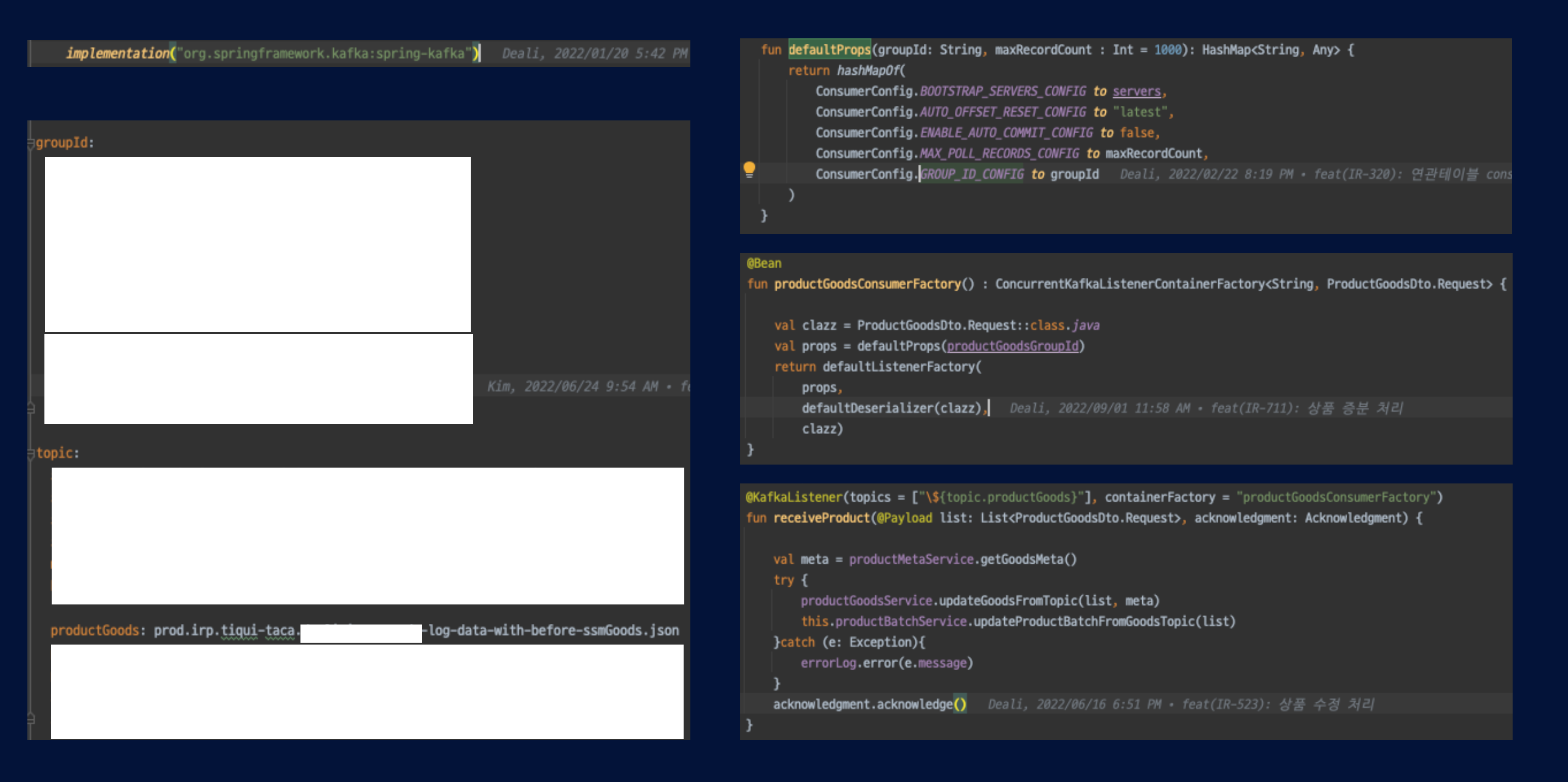
위 그림처럼
- spring-kafka 설정
- groupId 설정
- Topic 이름 설정
- ConsumerConfig 설정
- KafkaListener 설정
- KafaListener 개발
로 이루어져 있어서 간단한 설정으로 Consumer를 구성할 수 있습니다.
5) Result
이렇게 구성하여 상용 서비스에 적용한 결과입니다. 이번 프로젝트를 이전 상황과 간략히 비교해보면
- 전체색인
- AS-IS : xxxx만건 / 3시간 30분
- TO-BE : xxxx만건(AS-IS의 4배) / 40분
- 처리속도 80% 향상
- 증분색인
- AS-IS : 1분 ~ 3분 까지의 처리 속도
- TO-BE : 1초 ~ 20초 까지의 처리 속도
- 처리속도 90% 향상
- 데이터
- AS-IS : 색인 속도 때문에 활성화 상품만 색인
- TO-BE : 활성/비활성/삭제 포함 전체 상품 데이터 모두 색인(AS-IS 대비 4배)
- 상품 데이터량 400% 향상 + 다른 데이터 추가
성능 향상 효과는 매우 높은 수치를 보여주었습니다.
6) Future
이렇게 구성된 아키텍쳐를 통해 앞으로는 어떻게 더 발전할 것인가에 대해서 생각해 보았습니다.
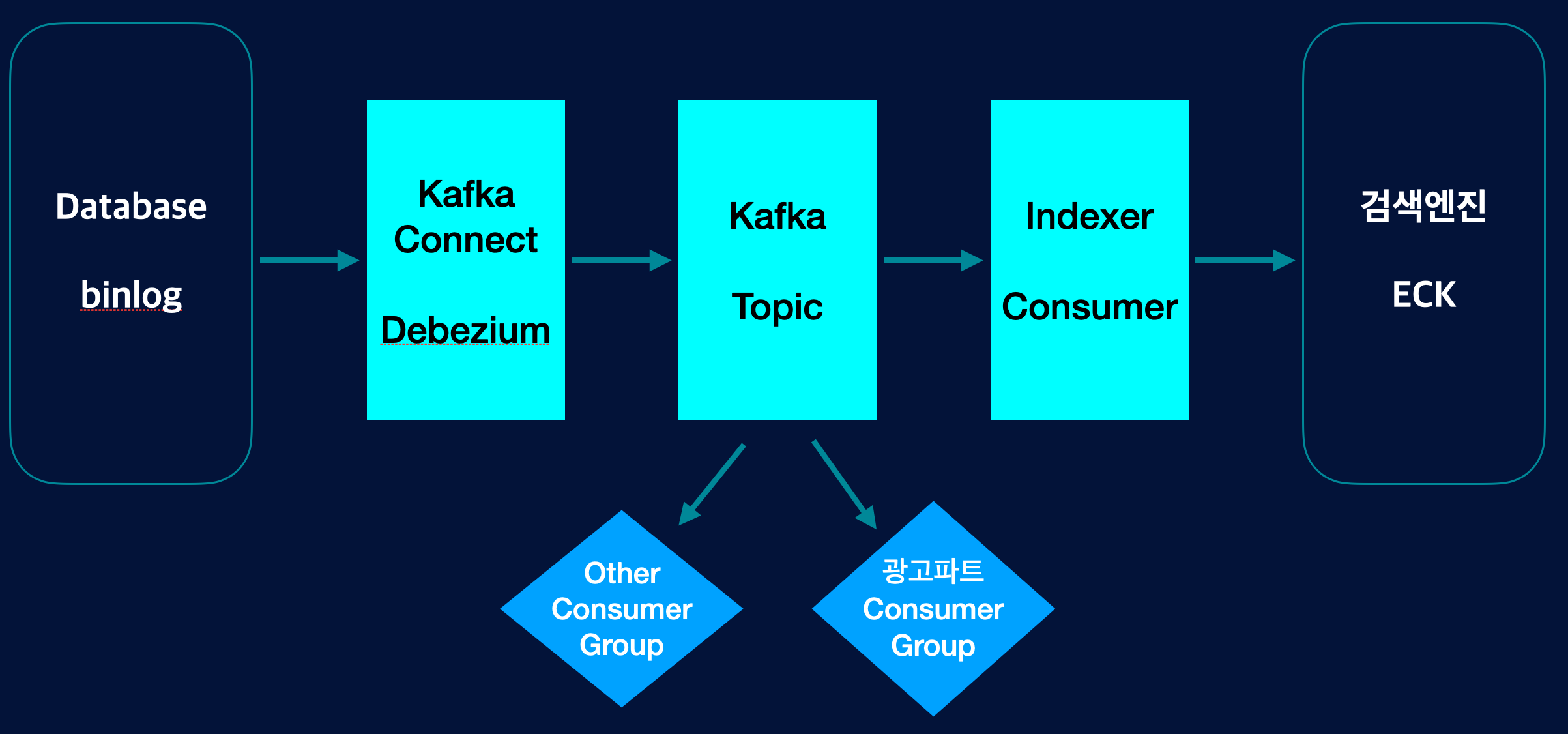
첫째로, 위 그림처럼 저희만 Topic Message를 사용하는 게 아니고 다른 파트에서도 이제 해당 Topic을 구독하여 사용할 수 있습니다. Consumer Group을 통해 독립적으로 Message를 사용할 수 있으며, 각자 파트에서 맡은 역할 및 로직에 대해서 책임을 분산할 수 있는 매우 중요한 효과가 있습니다.
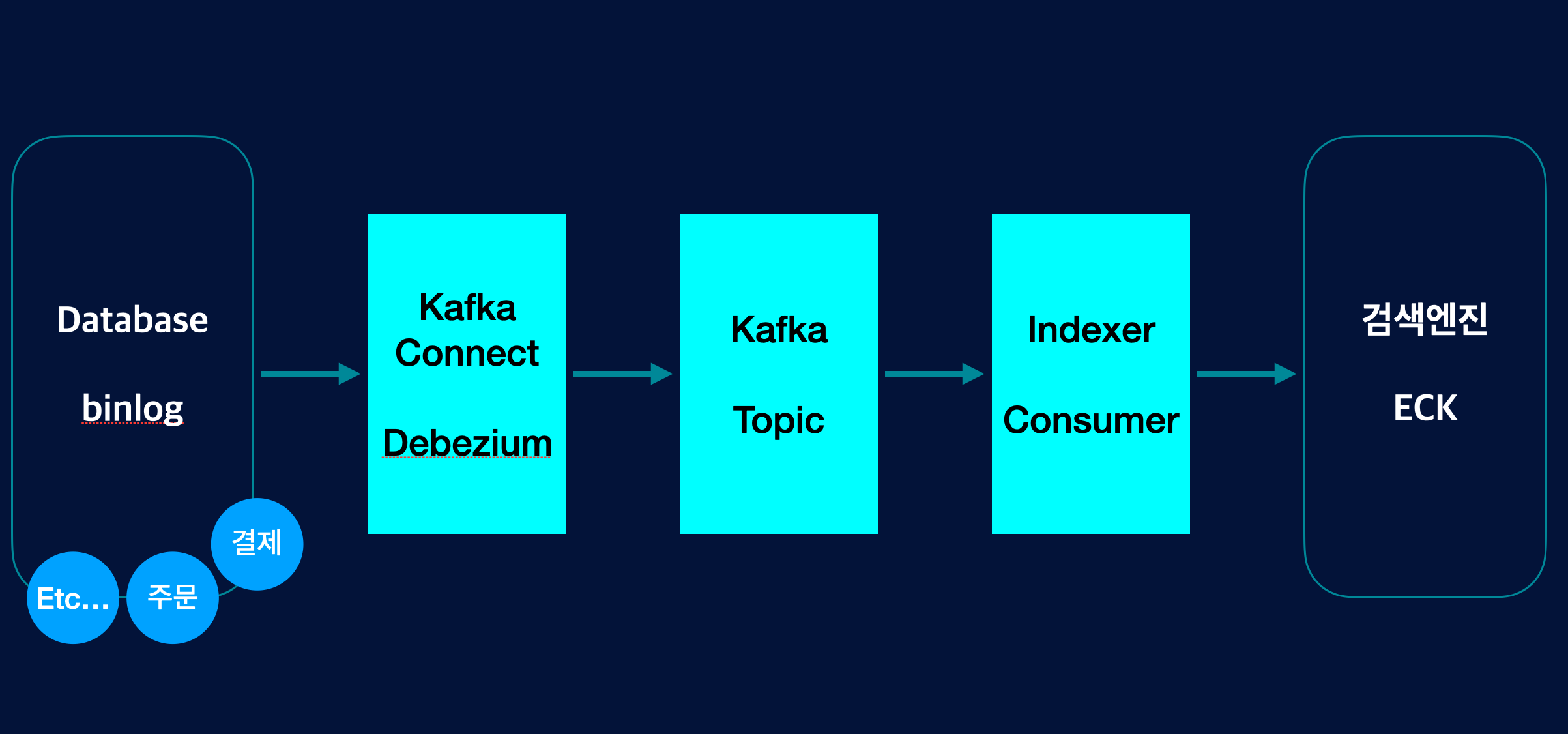
둘째로, Debezium을 통해 다양한 Dabase 데이터를 쉽게 가져올 수 있습니다. 주문, 결제 데이터 등 좀 더 다양한 검색로직 향상을 위해 필요한 데이터를 가져와 활용할 수 있는 환경이 구축되었습니다.
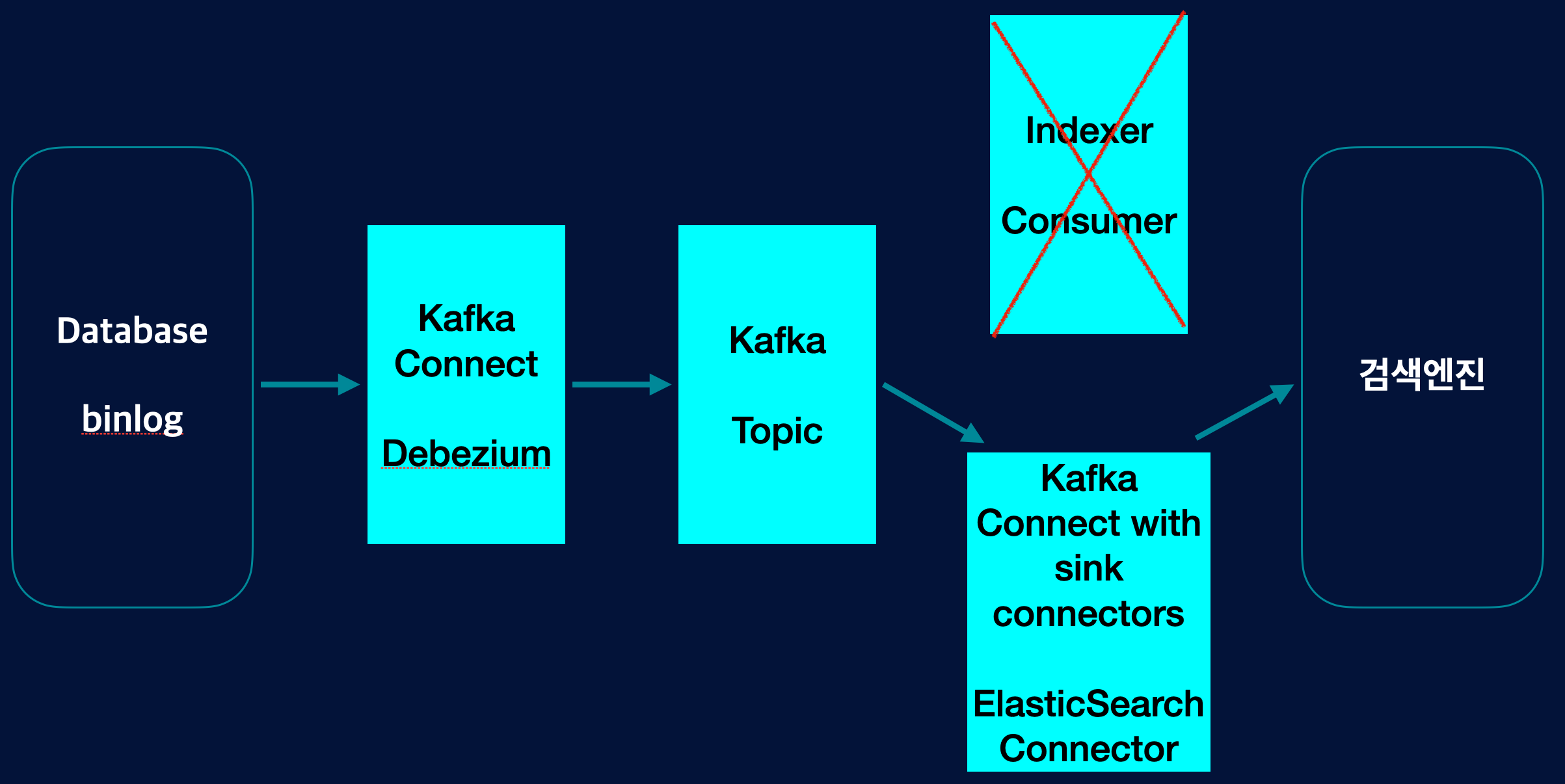
셋째로, Indexer Consumer Application도 없앨 수 있습니다. Kafka에서 sink Connector를 활용하면 Consumer도 구성할 수가 있습니다. Application 없이도 데이터를 검색엔진에 색인할 수 있는 구조가 될 것입니다.
마무리
약 6개월간 진행했던 프로젝트가 큰 이슈 없이 안정적으로 서비스할 수 있어서 매우 만족스러운 프로젝트였습니다. 진행한 프로젝트의 주요 키워드를 3가지로 요약하면 다음과 같습니다.
- 안정적인 검색엔진 운영
Spec Up, Scale Up, Snapshot, Version Up, Plugin install - 더 나은 협업
향상된 검색 품질/속도로 더 많은 데이터를 제공해 협업 시 다양한 시도 가능 - 80% 실행
변화에 빠르게 대응할 수 있는 구조가 되어서 다양한 시도를 애자일하게 실행
긴 글 끝까지 읽어주셔서 감사합니다.

장중수
딜리셔스 백엔드 개발자
"No Pain, No Gain"