딜리버드는 소매 사장님들이 사업을 쉽고 편하게 할 수 있도록 사입(동대문의 도매에서 옷을 구매하는 행위) - 검수/검품 - 고객배송까지 도와드리는 올인원 서비스입니다. 소매 사장님들 사이에서는 이미 유명한 서비스이지만, 해외배송을 런칭하고 NFA(Naver Fulfillment Alliance)에 참여하는 등 여전히 가파른 성장세를 지속하고 있습니다.

검색 결과 나오기까지 약 10초
딜리버드 관리자 페이지에는 WMS 데이터와 딜리버드의 데이터가 일치하지 않을 경우, 현재부터 과거까지의 전체 주문 중 특정 주문을 검색하여 배송 상태값을 업데이트하는 페이지가 있습니다. 기존에는
- RDB 주문 테이블, 주문 상품 테이블, 주소 테이블 세 개를 JOIN해서
- SQL LIKE 연산자로
주문을 검색하고 있었습니다. 서비스가 성장함에따라 데이터가 증가하면서 검색 속도도 느려졌는데요, 주문 하나를 검색하는데 9.87초가 걸리고 있었습니다. 서비스가 급성장 중이라 굵직한 기능 개발이 매우 많았고, 자주 쓰이는 페이지도 아니라서 우선순위가 밀리다보니 이렇게 되었네요.
 ES 적용 전 검색 10초
ES 적용 전 검색 10초
그러던 중, 서비스개발팀만의 ES 환경을 구축할 건데 딜리버드에도 적용해보는 게 어떻겠냐는 팀장님의 권유로 해당 페이지부터 Elasticsearch를 적용하게 되었습니다.
 7.13버전을 기준으로 설명합니다.
7.13버전을 기준으로 설명합니다.
Access pattern 정의하기
ES는 인덱스를 한 번 구성하면 새로운 필드를 추가할 순 있어도 기존에 존재하는 필드 타입을 변경하거나 삭제할 수 없습니다. 매핑을 변경하는 것이 간단하지 않기 때문에 access pattern을 명확히 해야 합니다.
딜리버드의 주문 정보는 orders, order_items, address 세 테이블에 담깁니다. 아래에 표기된 컬럼으로 검색할 수 있게 만드는 것이 목표입니다.
| orders | 주문 테이블 |
|---|---|
| id | 주문 id (PK) |
| invoice | 송장번호 |
| invoice_abroad | 해외 송장번호 |
| custom_no | 고객사주문번호 |
| … | … |
| order_items | 주문 상품 테이블 |
|---|---|
| id | 상품 id (검색X) |
| order_id | 주문 id (FK) |
| name | 상품명 |
| option1 | 상품 옵션1 |
| option2 | 상품 옵션2 |
| name_for_sale | 판매상품명 |
| … | … |
| address | 주소 테이블 |
|---|---|
| id | 주소 id (PK; 검색X) |
| order_id | 주문 id (FK) |
| partition | 받는 사람인지 보내는 사람인지 (검색X) |
| name | 이름 |
| phone_number | 전화번호 |
| address1 | 주소1 |
| address2 | 주소2 |
| … | … |
주의할 점은 관리자 페이지 특성상 구글처럼 무조건 연관성 순으로 결과를 노출할 필요는 없다는 것입니다. 관리자 페이지를 이용하는 관리자는 CS를 위해 특정 주문id, 송장번호, 받는 사람 핸드폰 번호 등의 검색어와 완전 일치하는 검색 결과만을 보고싶어합니다.
- Access pattern 1: 주문id, 송장번호, 해외 송장번호, 고객사주문번호, 받는 사람 이름, 받는 사람 전화번호로 검색하면 완전 일치하는 검색 결과를 가져와야 한다.
주문 정보 인덱스는 고객 전용 페이지에도 적용할 예정입니다. 딜리버드 서비스 특성상 이용자가 소매 사장님이기 때문에, 관리자와 마찬가지로 CS를 위해 access pattern 1이 필요하다는 점은 자명합니다. 여기에 더해, 소매 하나가 판매하는 상품의 양이 예상 외로 매우 많기 때문에 소매 사장님들이 자신이 판매하는 상품들의 상품명과 옵션을 정확히 기억하기는 힘들 것이라 예상합니다. 따라서 주문 상품명과 옵션으로 검색했을 땐 검색어와의 유사도 순으로 관련된 검색 결과들을 보여주는 것이 좋을 것이란 생각이 듭니다. 검색 결과 리스트에는 받는 사람 주소도 보여주기 때문에 주소로도 검색 가능하게 하는 것이 UX 측면에서 그럴듯해 보입니다.
- Access pattern 2: 상품명, 상품 옵션, 판매상품명, 받는 사람 주소로 검색하면 관련된 검색 결과들을 유사도 순으로 가져와야 한다.
필드 매핑 정의하기
주문id, 송장번호 같은 건 완전일치하는 결과만 나와야하고, 그 외의 검색어는 유사한 결과들이 나오면 된다고 했는데 사용자가 입력하는 검색어가 상품명인지, 송장번호인지 어떻게 구분하나요?
정규표현식으로 분기 처리하기에는 완전 일치 검색을 해야하는 고객사 주문번호의 경우 아스키코드 말고도 이모지만 아니면 아무 문자나 다 들어갈 수 있어서 애매합니다. 그래서 완전히 일치하는 검색 결과만 나와야 하는 필드들을 대상으로 먼저 filter 검색을 해보고, 결과가 없으면 나머지 필드들을 대상으로 multi-field match 검색을 하려고 합니다.
완전 일치하는 결과만 나와야 하는 필드들은 값이 일치하는지 단순 비교만하면 되니 토큰화 과정을 거칠 필요가 없습니다. 그러니 그 필드들은 타입을 분석기가 필요 없는 keyword로 지정하고, 나머지는 text로 지정하겠습니다.
- 주문id, 송장번호, 해외 송장번호, 고객사주문번호, 받는 사람 이름, 받는 사람 전화번호 타입 -> keyword
- 상품명, 상품 옵션, 판매상품명, 받는 사람 주소 타입 -> text
다만 딜리버드는 현재 일본향 해외배송을 런칭한 상태라 판매상품명(소매 쇼핑몰에 보여지는 상품명)과 받는 사람 주소 필드의 경우 한국어와 일본어, 영어 데이터가 들어온다는 점을 고려해야 합니다.
ES는 우리가 인덱스를 생성할 때 필드 별로 내부 인덱스를 따로 만듭니다. 한국어 분석기인 nori 만으로는 일본어와 영어 토큰을 제대로 생성하지 못하므로, 일본어 분석기인 kuromoji와 영어 분석기인 english를 적용할 내부 인덱스가 추가로 필요합니다. 이 문제는 필드 안에 multi field를 설정해주면 해결됩니다. 주문 상품을 기준(item_id를 document id로 저장)으로 도큐먼트를 저장할 건데요, 아래와 같이 주문 상품 하나 당 도큐먼트가 하나씩 생성되도록 매핑을 설정하면 item_name_for_sale에 판매상품명이 저장될 때 item_name_for_sale에는 nori로 분석한 토큰들이, item_name_for_sale.japanese에는 kuromoji로 분석한 토큰들이, item_name_for_sale.english에는 english로 분석한 토큰들이 저장됩니다.
{
"mappings": {
"properties": {
"item_name": {
"type": "text",
"analyzer": "nori"
},
"item_option": {
"type": "text",
"analyzer": "nori"
},
"item_name_for_sale": {
"type": "text",
"analyzer": "nori",
"fields": {
"japanese": {
"type": "text",
"analyzer": "kuromoji"
},
"english": {
"type": "text",
"analyzer": "english"
}
}
},
"order_id": {
"type": "keyword"
},
"order_invoice": {
"type": "keyword"
},
"order_invoice_abroad": {
"type": "keyword"
},
"order_custom_no": {
"type": "keyword"
},
"receiver_name": {
"type": "text",
"analyzer": "keyword"
},
"receiver_phone_number": {
"type": "text",
"analyzer": "keyword"
},
"receiver_address": {
"type": "text",
"analyzer": "nori",
"fields": {
"japanese": {
"type": "text",
"analyzer": "kuromoji"
},
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
검색 쿼리 정하기
Access pattern 1. 완전 일치 검색
타입이 keyword인 필드 중 하나의 필드값이라도 일치하면 검색 결과를 가져옵니다. should 쿼리는 검색어에 해당하는 도큐먼트의 점수를 높여주는데요, 어차피 다 일치하는 결과일테고, 개수가 적어서 한 페이지 안에 모두 노출될 것이기 때문에 검색 결과의 순서를 따질 필요가 없습니다. 연관성 점수를 계산할 필요가 없기 때문에 filter 쿼리로 should 쿼리를 감쌌습니다.
{
"query": {
"bool": {
"filter": {
"bool": {
"should": [
{ "term": { "order_id": "{검색어}" } },
{ "term": { "order_invoice": "{검색어}" } },
{ "term": { "order_invoice_abroad": "{검색어}" } },
...
]
}
}
}
}
}
Access pattern 2. Multi-field match 검색
Multi-field match의 검색 타입에는 여러가지가 있습니다. 디폴트 타입인 best_field로 검색해보겠습니다.
{
"query": {
"multi_match": {
"query": "가을 원피스",
"type": "best_fields",
"fields": ["item_name", "item_option", "item_name_for_sale*", "receiver_address*"]
}
}
}
앗.. 상품명 또는 판매상품명에 가을 원피스가 포함된 도큐먼트가 최상단에 노출될 것이라 예상했는데, 주소와 상품 옵션 필드에 원피스가 포함된 검색 결과들이 최상위에 나타납니다. 상호명이 원피스인 가게가 있나보네요. 두번째 도큐먼트는 보통 옵션 필드에는 사이즈나 색상 등을 기입하는데, 고객분이 원피스임을 강조하고 싶으셨나봅니다. (보안 문제로 인해 가을 과 원피스 키워드를 제외한 나머지 정보는 …으로 대체하였습니다)
{
"took" : 17,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : 14.366808,
"hits" : [
{
"_index" : "order_info",
"_type" : "_doc",
"_id" : "1111111",
"_score" : 14.366808,
"_source" : {
"item_name" : "...",
"item_option" : [
"..."
],
"item_name_for_sale" : "...",
"order_id" : "...",
"order_invoice" : "...",
"order_invoice_abroad" : "",
"order_custom_no" : "...",
"receiver_name" : "...",
"receiver_phone_number" : [
"..."
],
"receiver_address" : [
"... 원피스"
]
}
},
{
"_index" : "order_info",
"_type" : "_doc",
"_id" : "2222222",
"_score" : 12.482021,
"_source" : {
"item_name" : "...원피스...",
"item_option" : [
"원피스",
"원피스"
],
"item_name_for_sale" : "...원피스...",
"order_id" : "...",
"invoice_number" : "...",
"local_tracking_no" : "",
"order_custom_no" : "",
"receiver_name" : "...",
"receiver_phone_number" : [
"...",
"..."
],
"receiver_address" : [
"...",
"..."
]
}
},
...
]
}
}
best field 타입은 여러 필드에서 연관성 점수를 계산하고 그 중 최대값을 차용하는 검색입니다. 즉, 가을과 원피스 토큰 두개를 item_name, item_option, item_name_for_sale, item_name_for_sale.japanese, item_name_for_sale.english, receiver_address, receiver_address.japanese, receiver_address.english 8개 내부 인덱스에서 검색해서 필드별로 가장 높은 점수를 구한 후, 그 8개의 점수 중 가장 높은 값이 해당 도큐먼트의 점수가 되는 것입니다. 그런데 결과를 보니 연관성이 그다지 높아보이진 않습니다.
연관성 점수를 좌우하는 항: $IDF$
ES는 자바 기반 오픈소스 검색 엔진인 Lucene을 기반으로 만들어졌습니다. Lucene은 하나의 도큐먼트를 여러 단어들의 묶음으로 간주합니다(Bag-of-words model). 연관성 점수를 계산할 때 단어의 순서나 문법 따위는 고려하지 않고, 오직 해당 도큐먼트에 검색어가 몇 번 나타나는지만 고려하는 것이죠. 하나의 도큐먼트에 검색어가 여러번 등장할 수록 연관성이 높아집니다(Term frequency). 다만, 해당 검색어가 인덱스 안에 있는 매우 많은 도큐먼트에 등장한다면 중요도가 떨어지는 단어라고 간주해 연관성 점수를 낮춥니다(Inversed document frequency).
n개의 검색어 $q_1, q_2, … q_n$가 포함되어있는 검색 쿼리 $Q$와 어떤 도큐먼트 $D$ 사이의 연관성 점수 $score(D, Q)$는 아래과 같이 TF-IDF 알고리즘을 약간 변형한 BM25알고리즘을 이용하여 산출합니다. 원래 term saturation parameter $k_1$과 length normalization parameter $b$는 임의의 실수인데요, ES에서는 디폴트로 $k_1$과 $b$ 값을 1.2와 0.75로 설정해서 계산하고 있습니다. BM25에 두 값을 대입하면 다음과 같은 식이 됩니다.
$ score(D, Q) = (1+1.2)\sum_{i=1}^{n}ln\left(\frac{N-n(q_i)+0.5}{n(q_i)+0.5}+1\right)\cdot\frac{f(q_i,D)}{f(q_i,D)+1.2\cdot\left(1-0.75+0.75\cdot\frac{|D|}{avgdl}\right)} $
여기서 각 문자는 다음을 의미합니다.
- $N$ := 도큐먼트의 전체 개수
- $n(q_i)$ := 검색어 q_i를 포함하는 도큐먼트의 개수
- $f(q_i, D)$ := 도큐먼트 D에 검색어 q_i가 등장하는 횟수
- $|D|$ := 도큐먼트 D의 길이(즉, 토큰화했을 때 토큰의 개수)
- $avgdl$ := 전체 도큐먼트의 평균 길이
먼저, 시그마 안의 왼쪽 항(IDF)을 살펴보겠습니다.
$ ln\left(\frac{N-n(q_i)+0.5}{n(q_i)+0.5}+1\right) = ln\left(\frac{N+1}{n(q_i)+0.5}\right) \space =:IDF $
도큐먼트 전체 개수 $N$에는 비례하고, 검색어 $q_i$를 포함하는 도큐먼트의 개수 $n(q_i)$에는 반비례하면서, $n(q_i)$ 값이 작을 때 $IDF$값이 무지막지하게 커지지 않도록 분모에 0.5를 더하고 전체 항에 로그를 취해주었네요. item_name 필드를 기준으로 $n(q_i)$와 $IDF$ 값의 관계를 그래프로 그려보겠습니다. item_name 필드에 있는 도큐먼트 전체 개수 $N$은 1,134,059개이므로 다음과 같습니다.
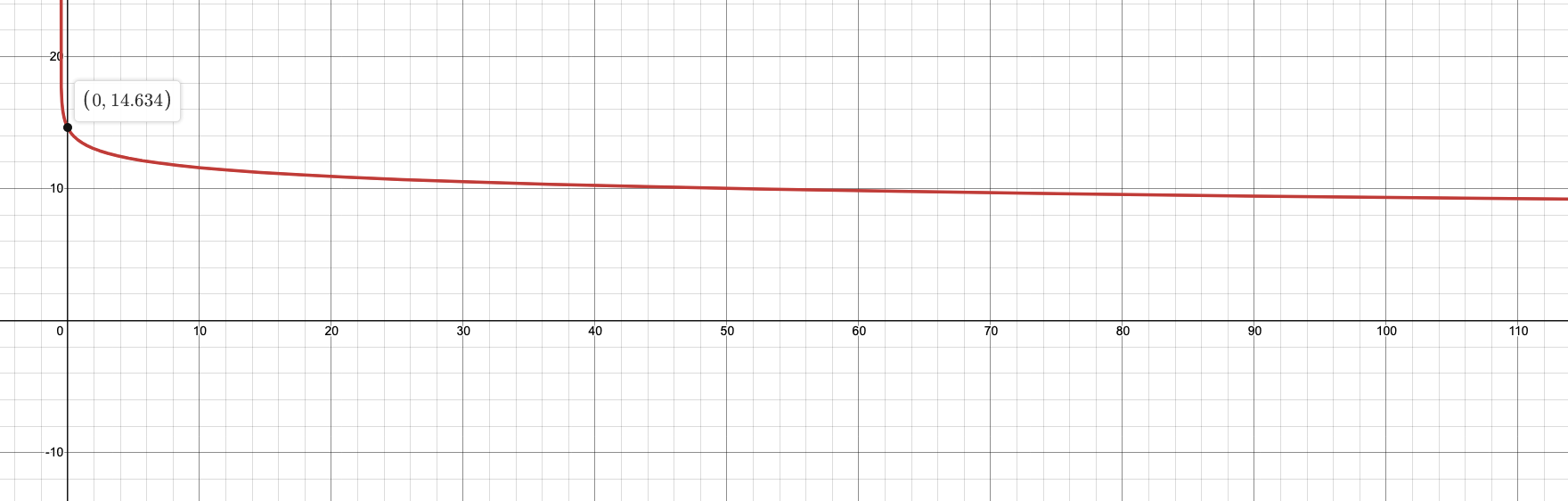 $IDF$
$IDF$
$n(q_i)$가 $N$일 때 $IDF$ 값은 거의 0입니다. 따라서 다음과 같이 간주할 수 있습니다.
$ IDF \in (0, 14.634) $
이번에는 시그마 안의 오른쪽 항($TF$)를 살펴보겠습니다.
$ \frac{f(q_i,D)}{f(q_i,D)+1.2\cdot\left(1-0.75+0.75\cdot\frac{|D|}{avgdl}\right)} = \frac{f(q_i,D)}{f(q_i,D)+0.9\frac{|D|}{avgdl}+0.3} = 1 - \frac{0.9\frac{|D|}{avgdl}+0.3}{f(q_i,D)+0.9\frac{|D|}{avgdl}+0.3} \space =:TF $
(세번째 항)도큐먼트 $D$에 검색어 $q_i$가 등장하는 횟수 $f(q_i, D)$가 분모에 있고 분자가 음수인 유리함수네요. $f(q_i, D)$값이 커질 수록 $TF$값이 증가하지만, $x=1$이 점근선이라 1 이상 커질 수 없습니다. 딜리버드 데이터들을 보면 가을 신상 인기 최고 가죽 스커트나 블랙과 같이 키워드 또는 짧은 단어들의 나열이기 때문에 하나의 문서에 같은 단어가 최대 2번 정도 등장합니다. 따라서 $f(q_i, D)$값이 1일 때(빨간선)와 2일 때(파란선) $\frac{|D|}{avgdl}$ 값과 $TF$ 값의 관계를 그래프로 그려보겠습니다. (두번째 항)
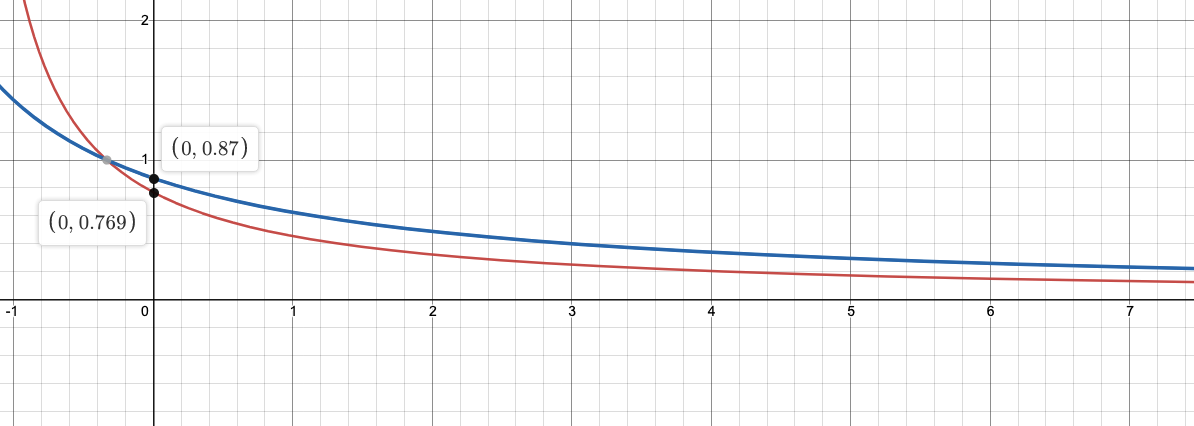 $TF$
$TF$
전체 도큐먼트의 평균 길이 avgdl은 필드별로 고정되어있는 값이고, 도큐먼트의 길이 $|D|$이 변수인데 이또한 딜리버드 데이터의 특성상 필드별로 들어가는 데이터가 비슷비슷하다보니 $avgdl$과 별 차이가 안 납니다. $|D|$가 최대 $avgdl$의 2배 정도까지 길어질 수 있다고 치면 다음과 같이 간주할 수 있습니다. $f(q_i, D) = 1, |D|/avgdl = 2$일 때 $TF$값은 0.323입니다.
$ TF \in [0.323, 0.87) $
이제 IDF와 TF의 범위를 비교해봅시다. 값의 범위를 구할 때의 조건이 다르니 직접적으로 비교하긴 어렵지만, IDF의 값의 범위가 TF 값보다 훨씬 더 넓다는 것을 알 수 있습니다. 즉, ES가 딜리버드의 주문 데이터를 기반으로 검색어와 도큐먼트 사이의 연관성 점수를 산출할 때, 도큐먼트에 검색어가 몇 번 등장하는지보다 도큐먼트 전체에서 얼마나 희귀한 단어인지가 점수를 좌우한다고 볼 수 있습니다.
위에서 best_field 타입으로 검색했을 때, 가을과 원피스라는 토큰이 상품명, 판매상품명 필드에서는 흔한 반면 상품옵션 필드와 받는 사람 주소 필드에서는 매우 희귀했기 때문에 검색 결과 최상단에 노출된 것이었습니다. 이런 사태를 막으려면 IDF 값을 조정할 필요가 있어 보입니다. 사실 item_name, item_option, item_name_for_sale, receiver_address의 데이터들은 굳이 다른 필드에 저장할 필요는 없습니다. 필드 별 중요도가 비슷해서 가중치를 줘야하는 필드가 딱히 없기 때문입니다.(다만 필드 별 필터링을 할 경우를 대비해 필드를 나눠놓았습니다.) 검색을 위해 네 필드의 데이터를 한꺼번에 저장하는 새로운 필드를 추가해야 할까요?
$IDF$값을 normalize하는 cross field 타입 검색
이 문제는 cross field 타입 검색이 해결해줄 수 있습니다. 공식문서를 보면 cross field 타입 검색은 위와 같은 문제를 해결하기 위해 필드 중심 쿼리가 아닌, term(검색어) 중심 쿼리로 검색할 수 있게 해준다고 합니다.
The cross_fields type is particularly useful with structured documents where multiple fields should match. For instance, when querying the first_name and last_name fields for “Will Smith”, the best match is likely to have “Will” in one field and “Smith” in the other.
This sounds like a job for most_fields but there are two problems with that approach. The first problem is that operator and minimum_should_match are applied per-field, instead of per-term (see explanation above).
The second problem is to do with relevance: the different term frequencies in the first_name and last_name fields can produce unexpected results.
For instance, imagine we have two people: “Will Smith” and “Smith Jones”. “Smith” as a last name is very common (and so is of low importance) but “Smith” as a first name is very uncommon (and so is of great importance).
If we do a search for “Will Smith”, the “Smith Jones” document will probably appear above the better matching “Will Smith” because the score of first_name:smith has trumped the combined scores of first_name:will plus last_name:smith.
One way of dealing with these types of queries is simply to index the first_name and last_name fields into a single full_name field. Of course, this can only be done at index time.
The cross_field type tries to solve these problems at query time by taking a term-centric approach. It first analyzes the query string into individual terms, then looks for each term in any of the fields, as though they were one big field.
마치 하나의 커다란 필드에 데이터를 모두 집어넣은 것처럼 검색한다고 하네요. 그렇다면 쿼리 타임 동안 Lucene이 어떤 작업을 하길래 그런 걸까요? 새로운 인덱스를 만들어서 테스트해보겠습니다.
| field1 | field2 | field3 | |
|---|---|---|---|
| doc1 | 원피스 | 원피스 | 원피스 |
| doc2 | 모자 | 나시 | 원피스 |
| doc3 | 원피스 | 모자 | 나시 |
| doc4 | 모자 | 원피스 | 모자 |
필드 세 개의 도큐먼트를 모두 합쳐서 저장한 결과와 같아지려면 쿼리 타임 동안 TF와 IDF의 값을 다시 계산해야 합니다. 단순히 필드별 문서를 합쳐놓은 것과 같으므로 TF의 경우 한 행에 있는 TF들을 모두 더하면 됩니다. 반면, doc1처럼, 필드 별 도큐먼트가 포함하는 토큰이 중복되는 경우가 얼마나 있을지 몰라 필드별 IDF도 다 더할 순 없습니다. 그렇다고 쿼리 타임 동안 IDF를 다시 계산하기엔 검색 속도가 느려집니다.
검색할 때 아래와와 같이 explain 값을 true로 설정하면 점수가 어떻게 산출된 건지 확인할 수 있습니다. IDF값은 검색 쿼리의 _explanation 필드를 통해 확인해보겠습니다.
// 인덱스 생성
PUT cross_field_index
{
"mappings": {
"properties": {
"field1": {
"type": "text"
},
"field2": {
"type": "text"
},
"field3": {
"type": "text"
}
}
}
}
// 데이터 인덱싱
POST cross_field_index/_bulk
{"index": {"_id": "1"}}
{"field1": "원피스", "field2": "원피스", "field3": "원피스"}
{"index": {"_id": "2"}}
{"field1": "모자", "field2": "나시", "field3": "원피스"}
{"index": {"_id": "3"}}
{"field1": "원피스", "field2": "모자", "field3": "나시"}
{"index": {"_id": "4"}}
{"field1": "모자", "field2": "원피스", "field3": "모자"}
// 검색
GET cross_field_index/_search
{
"query": {
"multi_match": {
"query": "원피스",
"type": "cross_fields"
}
},
"explain": true
}
물론 검색 결과 첫번째에는 doc1이 있습니다. 응답의 _explanation 필드를 보시죠.
"_explanation" : {
"value" : 0.6931471,
"description" : "max of:",
"details" : [
{
"value" : 0.6931471,
"description" : "max of:",
"details" : [
{
"value" : 0.6931471,
"description" : "weight(field1:원피스 in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.6931471,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.6931472,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
...
n, number of documents containing term의 값이 2라고 나옵니다. 원피스는 도큐먼트 4개에 모두 존재하는데 말이죠.
Lucene은 쿼리 타임 동안 IDF 값을 다시 계산하는 대신, 필드별 최대 IDF 값을 차용하는 것을 선택했습니다.(최대 IDF 값을 사용하는 것이 디폴트인데, tie_breaker 값을 설정해서 최대 IDF 값에 일정한 가중치를 곱한 다른 IDF 값들을 더해서 사용할 수도 있습니다.) 정확성보다 속도를 선택한 것이죠. 연관성 점수가 하나의 필드에 데이터를 저장한 것과 완전히 일치하지는 않지만, 결과는 나름 만족스럽게 나옵니다.
{
"query": {
"multi_match": {
"query": "가을 원피스",
"type": "cross_fields",
"fields": ["item_name", "item_option", "item_name_for_sale*", "receiver_address*"]
}
}
}
{
"took" : 17,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : 9.096694,
"hits" : [
{
"_index" : "order_info",
"_type" : "_doc",
"_id" : "3333333",
"_score" : 9.096694,
"_source" : {
"item_name" : "...원피스...",
"item_option" : [
"..."
],
"item_name_for_sale" : "가을 니트 원피스",
"order_id" : "...",
"order_invoice" : "...",
"order_invoice_abroad" : "",
"order_custom_no" : "...",
"receiver_name" : "...",
"receiver_phone_number" : [
"..."
],
"receiver_address" : [
"...",
"..."
]
}
},
{
"_index" : "order_info",
"_type" : "_doc",
"_id" : "4444444",
"_score" : 9.096694,
"_source" : {
"item_name" : "...원피스",
"item_option" : [
"...",
"..."
],
"item_name_for_sale" : "가을 퍼프 원피스",
"order_id" : "...",
"invoice_number" : "...",
"local_tracking_no" : "",
"order_custom_no" : "",
"receiver_name" : "...",
"receiver_phone_number" : [
"...",
"..."
],
"receiver_address" : [
"...",
"..."
]
}
},
...
]
}
}
nori 추가 설정
다른 테스트를 여러번 하다 보니 또다른 문제를 발견했습니다. 일본어 주소 東京(도쿄)로 검색했는데 한국으로 배송된 주문 정보가 최상단에 위치한다는 점입니다. 확인해보니 원룸 빌딩 이름이 동경이네요.
{
"query": {
"multi_match": {
"query": "",
"type": "cross_fields",
"fields": ["item_name", "item_option", "item_name_for_sale*", "receiver_address*"]
}
}
}
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : 9.871733,
"hits" : [
{
"_index" : "order_info",
"_type" : "_doc",
"_id" : "5555555",
"_score" : 9.871733,
"_source" : {
"item_name" : "...",
"item_option" : [
"..."
],
"item_name_for_sale" : "...",
"order_id" : "...",
"order_invoice" : "...",
"order_invoice_abroad" : "",
"order_custom_no" : "...",
"receiver_name" : "...",
"receiver_phone_number" : [
"..."
],
"receiver_address" : [
"...동경..."
]
}
},
...,
{
"_index" : "order_info",
"_type" : "_doc",
"_id" : "6666666",
"_score" : 9.499645,
"_source" : {
"item_name" : "...",
"item_option" : [
"...",
"..."
],
"item_name_for_sale" : "...",
"order_id" : "...",
"invoice_number" : "...",
"local_tracking_no" : "",
"order_custom_no" : "",
"receiver_name" : "...",
"receiver_phone_number" : [
"...",
"..."
],
"receiver_address" : [
"東京...",
"..."
]
}
},
...
]
}
}
nori 분석기는 별다른 설정을 하지 않으면 세 개의 토큰 필터를 사용합니다:
- downcase: 영어 토큰을 소문자로 변환하여 저장
- reading_form: 한자 토큰을 한글(독음)으로 변환하여 저장
- part_of_speech: 명사, 동명사 등의 토큰은 저장하고 조사, 형용사 등의 토큰은 저장하지 않음
한글 주소 필드를 분석할 땐 reading_from 토큰 필터를 사용하지 않도록 다음과 같이 설정하면 해결됩니다.
PUT pps_order_infos
{
"settings": {
"analysis": {
"analyzer": {
"korean_address_analyzer": {
"tokenizer": "nori_tokenizer",
"filter": ["lowercase", "nori_part_of_speech"]
}
},
"char_filter": {
"serial_no_filter": {
"type": "pattern_replace",
"pattern": "[)(+-]",
"replacement": ""
}
}
}
},
"mappings": {
"properties": {
...,
"receiver_address": {
"type": "text",
"analyzer": "korean_address_analyzer",
"fields": {
"japanese": {
"type": "text",
"analyzer": "kuromoji"
},
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
적용 결과: 약 0.06초
ES 적용 결과 검색 시간이 0.057초로 줄어들었습니다!
 ES 적용 후 57ms
ES 적용 후 57ms
참고자료
- https://www.elastic.co/guide/en/elasticsearch/reference/7.13/index.html
- https://esbook.kimjmin.net/
- https://opensourceconnections.com/blog/2015/03/19/elasticsearch-cross-field-search-is-a-lie/
- https://en.wikipedia.org/wiki/Okapi_BM25
- https://en.wikipedia.org/wiki/Bag-of-words_model
 귀여니 ‘아웃사이더’ 中
귀여니 ‘아웃사이더’ 中

양혜진
서비스개발팀 딜리버드파트 주니어 개발자입니다
"긍정적으로 살자"