AI 파트에서는 현재 서비스 중인 ‘AI 상품 태그 정보’를 자체 기술로 변경하며 보다 나은 서비스를 제공하기 위해 기술 개발을 시작하였습니다. 그 과정에서 적용된 상품탐지 및 해시태그 분류 개발과정에 대해 공유하고자 합니다.
배경
현재 신상마켓에서 서비스중인 ‘AI 상품 태그 정보’(Fig.1)는 다음과 같은 한계가 있습니다.
- 일부 상품에만 태그 제공(‘AI 상품 태그 정보’가 없는 상품이 존재)
- 판매중인 상품의 태그만 제공(모델이 착용한 다양한 상품에 대한 tag는 제공하지 않음)
AI 파트에서는 object detection과 classification 기술을 도입하여 기존 단점을 보완함과 동시에 다음과 같은 추가 효과를 기대할 수 있을것으로 예상합니다.
- 도매 유저에게 상품 등록 시 모델이 착용중인 모든 상품의 태그정보를 자동으로 제안
- 소매 유저에게 다양한 해시태그를 제공

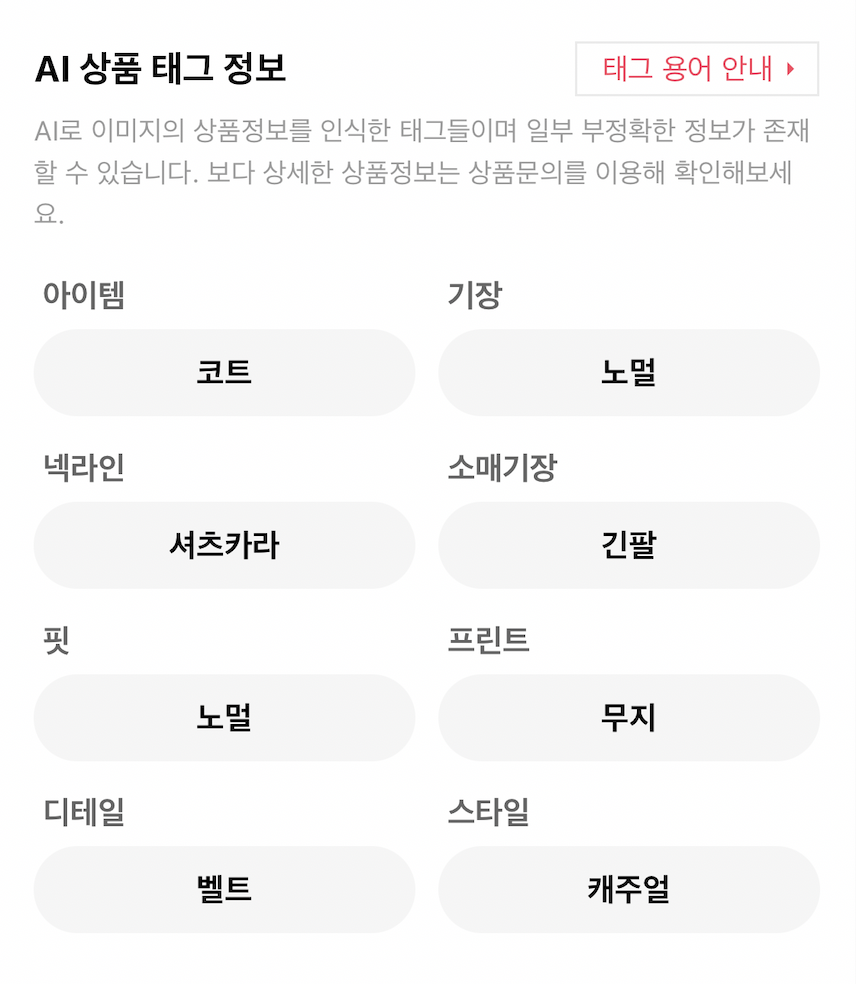
Fig. 1. 현재 서비스중인 HashTag 예시
기술개요
AI 파트에서는 Classification(분류)와 Object Detection(객체 탐지)기술로 개발을 진행했습니다.
Deep Learning에 익숙하지 않다면 Classification과 Object Detection이 어떤 기술인지 궁금하실겁니다. 간략하게 두 기술에 대해 소개해 보도록 하겠습니다.
Classification이란?
이미지를 분류하는 것으로 해당 이미지 내의 객체가 무엇인지 알려주는 것 입니다. 분류 문제는 분류할 것이 하나인지 여러가지인지에 따라 Single Label Classification, Multi Label Classification으로 나뉘게 됩니다.
- Single Label Classification : 분류해야할 객체가 여러 class중(3개 이상) 한가지인 경우를 Single Label Classification 혹은 Multi-Class Classification 이라 합니다.
- Multi Label Classification : 분류해야할 객체가 여러 class중 한가지 이상인 경우 Multi Label Classification이라 합니다.
간단한 예시를 들어볼까요?(Fig.2. 참고)
Samples은 분류해야 할 객체가 담긴 이미지이고, labels가 1이면 정답, 0이면 오답을 뜻합니다. 예시는 [해, 달, 구름] 세가지 class가 있을때, Single label의 경우 샘플이 구름일 경우 구름이라는 label만을 가지게 됩니다. 반면에 Multi label의 경우 샘플에 해와 구름이 있다면 정답도 두가지인것을 볼 수 있습니다.
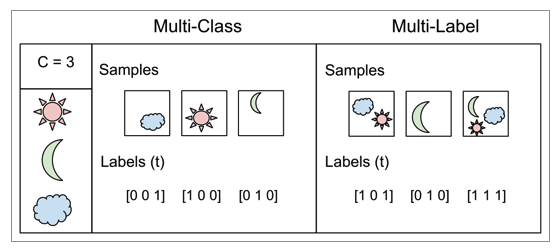
Fig.2. Single label VS Multi label
Object Detection이란?
Object Detection이란 이미지나 영상의 객체(objects)가 무엇인지 분류하고 객체의 위치까지 인식해주는 기술로 분류와 위치인식이 동시에 가능합니다.
하단의 그림은 Classification과 Object Detection의 예시입니다.
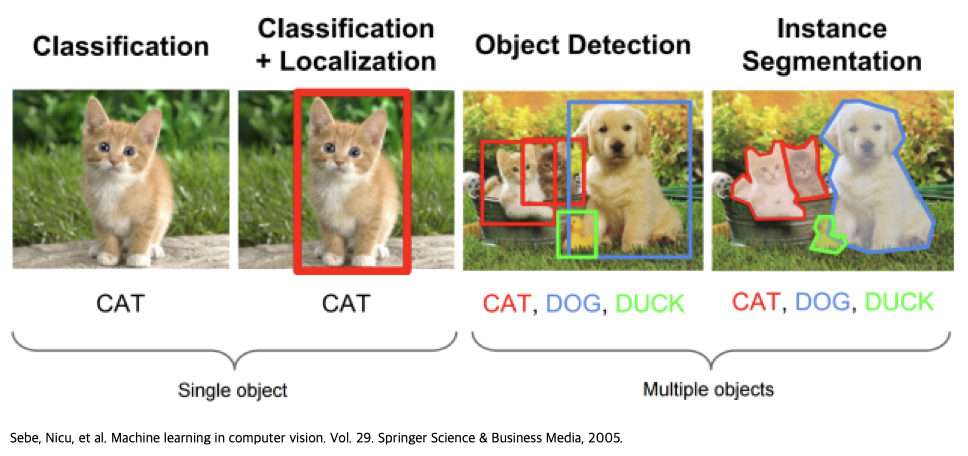
Fig.3. Classification vs Object Detection
이제 위의 두 가지 기술을 사용하여 우리가 풀고자 하는 문제에 대입해 보았습니다.
신상마켓의 상품 중엔 모델이 착용하고 있지만 판매하는 상품이 아닌 경우가 있습니다. 예를 들어 니트를 판매하는 상품의 썸네일이 니트와 아우터를 레이어드하여 입은 전신 이미지(Fig.4.)라면?

Fig.4. 데이터 예시
Fig.4. 이미지 출처 : https://pxhere.com/ko/photo/1605201
니트, 아우터, 하의에 대한 모든 특징 정보를 얻을 수 있지만, 그 중 판매 상품인 니트의 정보만 얻어내기 어렵습니다. 만약 각 상품 별로 분리된 이미지를 가지고 있다면 개별 특징 정보를 얻기 가장 쉬울 것입니다.
Object Detection을 이 문제에 대입해 보면 아래와 같습니다.
- 메인 카테고리인 ‘상의’, ‘하의’, ‘아우터’, ‘원피스’를 분류
- 각 카테고리의 위치 검출
이제 Object Detection 모델을 통해 각 카테고리와 해당 좌표를 얻어낼 수 있으니 다음으로 해시태그 분류 모델을 풀어보았습니다.
다양한 해시태그 중 ‘소매기장’, ‘기장’, ‘색상’에 대한 태그 값은 고유한 한가지 값을 가지게 됩니다. 반팔이며 긴팔일 수 없겠죠?
반면 ‘섬유소재’ 태그의 경우 여러 소재가 한가지 옷에 다양하게 사용될 수 있습니다.
이러한 문제를 Classification으로 풀어보면 아래와 같습니다.
- ‘소매기장’, ‘기장’, ‘색상’ → Single Label Classification
- ‘섬유소재’, ‘프린팅’ → Multi Label Classification
지금까지 위 두가지 기술을 사용하여 우리의 문제를 어떻게 해결 하였는지 알아보았습니다.
Issue
개발을 진행하며 몇가지 이슈가 존재했습니다.
- 내부 데이터의 정확도
- model inference 속도
- model의 성능 및 평가
내부 데이터의 정확도 문제
모델을 학습시키기 위해서는 정답이 필요합니다.(모델은 예측한 값을 맞췄는지 틀렸는지 여부에 따라 모델의 학습방향을 수정합니다)
우리가 학습시키고자 하는 Object Detection 모델은 ‘상의’, ‘하의’, ‘아우터’, ‘원피스’라는 정답과 해당 좌표값이 필요합니다. 하지만 현재 내부 데이터는 좌표값에 대한 정보가 없습니다. 또한 해시태그 모델의 정답으로 사용할 여러 속성 정보는 상품 등록시 도매 유저가 정한 title에서 추출하는 방법을 사용해야 합니다. 하지만 이는 데이터의 정답에 대한 신뢰도가 떨어지고, 각 해시태그 속성 정보를 고르게 수집할 수 없다는 문제점이 있었습니다. 그렇다고 이러한 문제점을 해결하기 위해 내부 데이터에 대한 annotation 작업을 따로 진행한다면 n개월 이상 시간이 소요될 것으로 예상되는 상황이었습니다.
그러던 와중 한국지능정보사회진흥원이 운영하는 ai-hub(AI 학습용 데이터 구축,확산 사업의 일환으로 AI 기술, 서비스 개발에 필수적인 AI 데이터, 소재정보 등을 제공하는 플랫폼)에서 k-fashion dataset이 올해 6월 첫 공개가 되었고 문제를 빠르고 단순하게 해결하기위해 open dataset인 k-fashion dataset을 사용하게되었습니다. (k-fasion에서 제공하는 데이터는 패션 전문가가 패션 영역의 활용성을 고려한 스타일 및 세부속성 분류를 구성하였고 Fig.5.에서 데이터의 구조를 볼 수 있습니다.)
k-fashion의 메인 카테고리는 ‘상의’, ‘하의’, ‘원피스’, ‘아우터’로 구성되어 있고, 각 메인 카테고리의 세부적인 카테고리 및 ‘기장’, ‘디테일’, ‘넥라인’, ‘프린트’, ‘색상’, ‘서브색상’, ‘핏’, ‘옷깃’, ‘소재’, ‘소매기장’, ‘스타일’, ‘서브스타일’에 대한 속성정보를 제공합니다.
우리는 이러한 속성정보 중 ‘기장’, ‘소매기장’, ‘프린트’, ‘색상’, ‘소재’를 우선적으로 선정하여 해시태그 모델 개발을 진행하였고 앞으로 다양한 속성정보를 추가할 예정입니다.
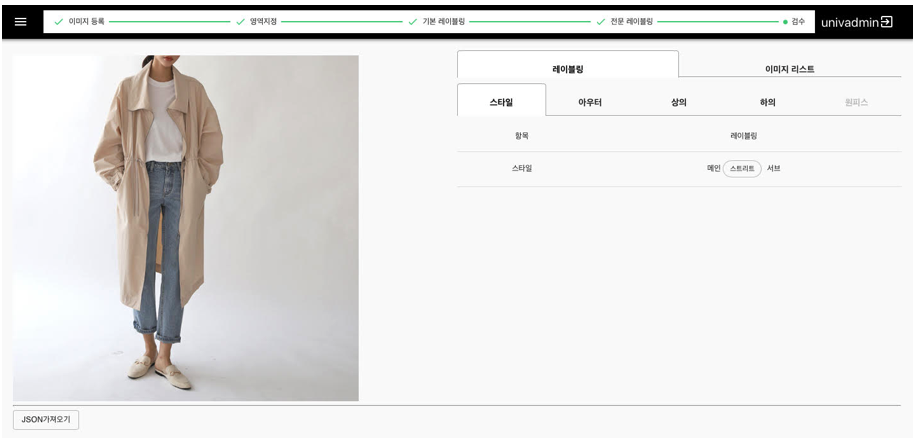
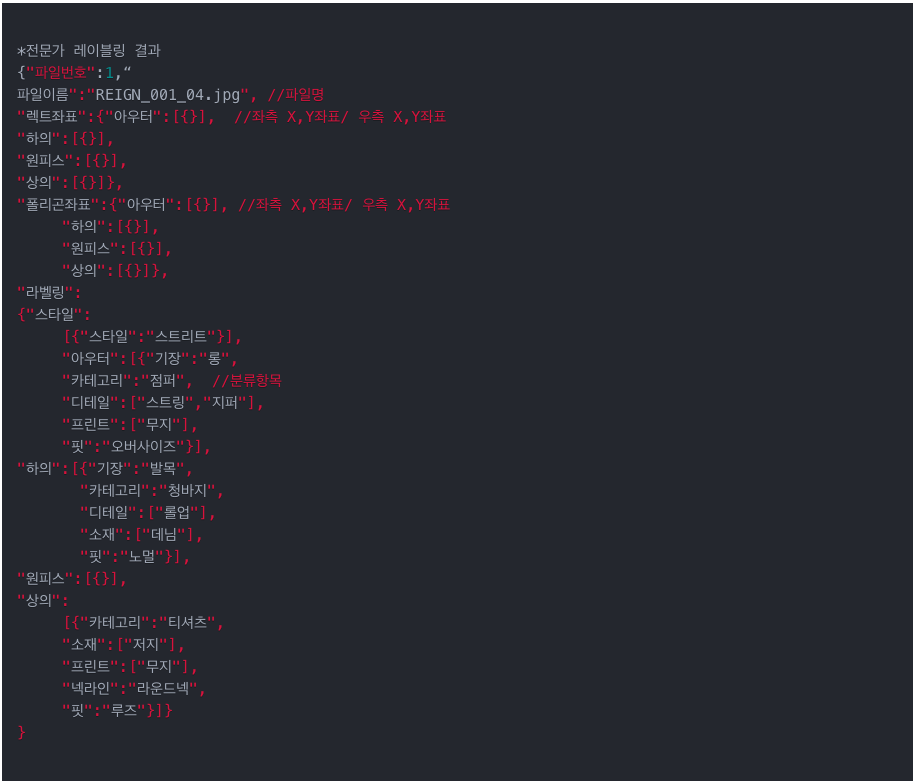
Fig.5. k-fasion dataset example
model inference 속도 문제
학습을 진행하기에 앞서 현재까지 나온 다양한 모델 중 어떤것을 선택해야 할지 고민하게 됩니다. 저는 Image Classification 문제를 public dataset인 ImageNet을 benchmark로 사용해 여러가지 모델 성능을 평가한 사이트를 참고하여 NFNet을 선택하게 되었습니다. (다양한 model의 성능이 궁금하시다면 해당 링크를 참고)
초기 프로젝트를 진행할 당시 NFNet이라는 Network가 새롭게 등장하며 State-Of-The-Art(SOTA)를 달성했고 그중 비교적 가벼운 F1 model을 선택하였습니다. 하지만 NFNet-F1은 parameter 수가 132.6M로 정확도는 비교적 높지만 속도 측면에서 단점이 있었습니다. (parameter수가 많다면 연산량이 많아진다고 볼 수 있습니다.)
이를 개선하기 위해 정확도는 NFNet과 비슷하며 조금 더 가벼운 모델인 EfficientNet V2 Large model로 변경하여 학습하였습니다. 모델을 변경하여 inference 속도가 800ms → 2~300 ms로, 약 3배이상 단축시킬 수 있었습니다.
model의 성능 및 평가 문제
데이터 특징
모델의 정확도는 데이터의 양과 질에 굉장히 민감합니다. k-fashion 을 통해 양질의 데이터를 얻을 수 있었지만 실제 신상마켓에 등록되는 데이터와 특징과 다른 경향이 있습니다.
- 옷걸이에 걸린 옷 존재
- 여러개의 옷이 겹쳐있는 경우 존재
- 모델의 얼굴 노출
이에 비해 k-fashion 데이터는 모델의 얼굴을 식별할 수 없도록 되어있으며 옷걸이에 걸린 옷이나 여러 장의 옷이 겹치는 샘플은 검수를 통해 포함되지 않도록 구성되어 있습니다.
k-fashion 데이터로 학습한 모델을 신상마켓 데이터에도 잘 동작하도록 하기위해 모델의 얼굴영역이 포함되지 않도록 데이터를 재구성 하였습니다. 또한 모델이 착용하지 않은 옷의 경우 Object Detection을 통해 옷의 좌표를 얻어내어 해당 영역에서 해시태그를 추출할 수 있도록 했습니다.

Fig.6. a) 신상마켓 데이터 특징 예시

Fig.6. b) k-fashion 데이터 예시
data imbalance 문제
k-fashion에서 다양한 label의 데이터를 구축하여 제공하고 있지만 label 별로 데이터의 수가 천차만별입니다. 이를 해결하기 위해 가장 적은 데이터수에 기준을 맞추는 under-sampling을 했습니다.
model 평가 문제
모델의 성능평가에 k-fashion 데이터만 사용한다면 내부 데이터에도 동일한 성능이라고 할 수 없습니다. 학습 과정에서는 k-fashion 데이터만 사용하기 때문에 학습 과정에서 모델을 평가하는 validation은 k-fashion 데이터를 사용하였고, 실제 서비스중인 신상마켓 데이터에 대한 성능 평가를 추가적으로 진행했습니다.
model 성능 개선 문제
모델의 성능을 개선하기 위해서 신상마켓의 데이터를 학습할 때 추가하는 방법이 있으나 현재 내부 데이터는 상품의 좌표값과 정확한 정답을 추출하는데 어려움이 있습니다. 이는 해시태그 서비스를 도입해 새롭게 추가되는 내부 데이터를 통해 모델 성능 개선을 할 수 있을것으로 예상됩니다.
데모 개발
의류 상품 이미지를 업로드하면 상품 종류를 탐지하고, 탐지된 의류는 해시태그 모델의 입력 이미지로 사용되어 각 의류 상품의 해시태그 결과를 추출하는 데모 페이지를 제작했습니다.
아래의 예시 이미지를 보면, 업로드 된 원본 이미지에서 ‘상의’와 ‘하의’가 탐지 되었고, 탐지된 상품별 해시태그는 하단의 테이블에서 나오게 됩니다. 추가적으로 테이블의 드롭다운(‘>’) 버튼을 눌러 모델이 예측한 해시태그의 확률값을 확인할 수 있습니다.
현재 개발 완료 된 해시태그 속성은 ‘소매기장’, ‘총장(기장)’, ‘소재’, ‘프린트’, ‘색상’으로, 향후 k-fashion에서 제공해 주는 다양한 속성값을 추가 학습할 예정입니다.

Fig.7. a) 데모 페이지 예시 1
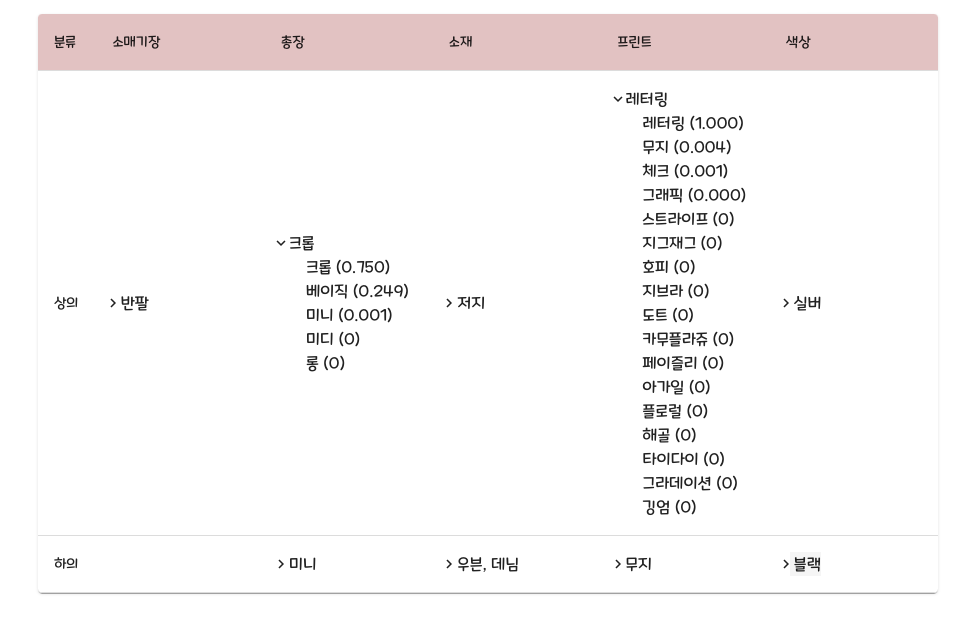
Fig.7. b) 데모 페이지 예시 2
추가 활용처
Object Detection을 활용한 이미지 검색 확대

Fig.8. 이미지 검색 기능 예시
‘이미지 검색 기능’은 소매 유저에게 관심 상품과 유사한 상품을 추천해 주는 서비스입니다. 하지만 현재의 이미지 검색 서비스는 몇가지 단점이 존재합니다.
- 사용자가 관심 영역을 직접 선택하여 crop 해야 함
- ‘원피스’ 카테고리에 한정적으로 제공
해당 기능을 모든 카테고리로 확장하기 위해서는 모든 상품의 카테고리를 분류하여 해당 카테고리에서 유사 이미지 검색을 해야합니다. 이번에 개발한 Object Detection model을 통해 이미지 내의 모든 상품의 위치와 카테고리를 추출할 수 있기 때문에 이미지 검색 기능의 확대 및 소비자가 직접 영역을 지정해야 하는 번거로움 또한 해결될 것으로 예상됩니다.
해시태그 필터 검색
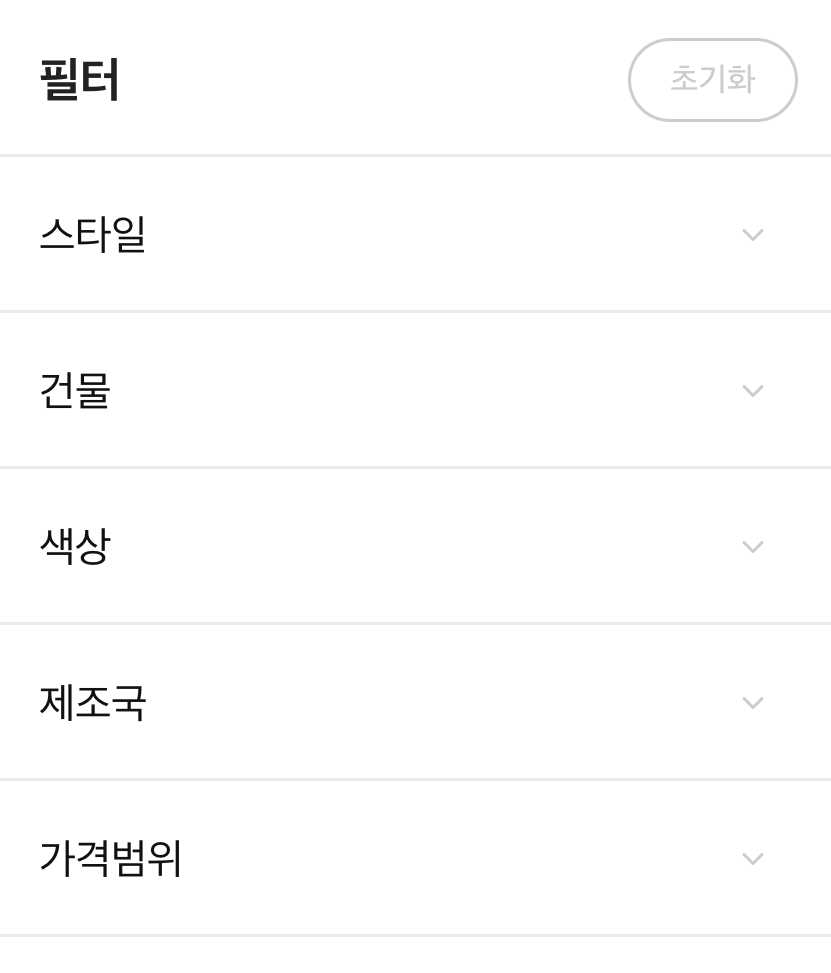
Fig.9. 신상마켓에서 제공중인 필터 옵션
현재 제공하고 있는 검색 필터의 옵션은 ‘스타일’, ‘건물(도매업체)’, ‘색상’, ‘제조국’, ‘가격범위’ 입니다.(Fig.9.) 해시태그 모델을 통해 상품의 다양한 속성정보를 얻을 수 있으며, 이를 필터의 옵션으로 활용할 수 있습니다. 또한 유사 이미지 검색 기능에 해시태그 속성을 필터 옵션으로 제공하면 더욱 정밀한 검색이 가능해질 것으로 기대합니다.

윤주영
딜리셔스 ML 엔지니어
"너는 뭐가 되려고 그러니"