딜리셔스는 광고를 집행하는 도매에게 광고 사용 현황과 통계 결과를 확인 할 수 있는 ‘신상애드’ 서비스를 제공하고 있습니다. 여기서는 광고 상품별로 노출, 클릭, 찜, 매장 방문과 같은 유저의 행동 데이터와 광고 집행 비용에 대한 결과 메트릭을 광고주에게 제공함으로써 광고 집행의 효과를 쉽게 확인 할 수 있습니다.
행동 데이터 및 광고 집행 비용에 대한 데이터는 현재 딜리셔스의 DI(Data Integration) 파트에서 다루고 있으며, 이번 글에서는 데이터 서비스를 하기 위한 Non-Aggregation Real-time 분석시스템에 대해 설명하도록 하겠습니다.
도입 배경
도입 배경을 설명하기 위해 기존 데이터 처리 과정을 살펴 보겠습니다.
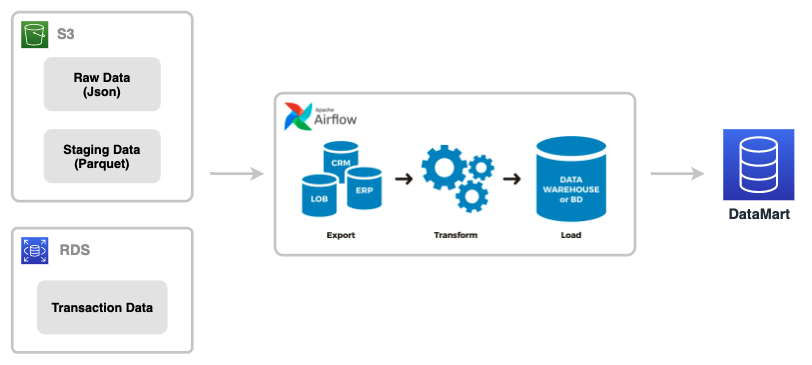
신상애드 메트릭 지표를 만들기 위해서는 고객의 행동 데이터와 RDB의 OLTP 데이터가 필요합니다. 고객의 행동 데이터는 JSON으로 들어오며, 정제하는 과정을 거쳐 Parquet 형식으로 S3에 보관되고 이 중 OLTP 데이터는 RDB로 저장됩니다. 이렇게 저장된 데이터는 Airlow 배치 스케줄러를 통해 ETL과정을 거친 후 데이터 마트로 생성됩니다.
기존 Airflow 배치의 가장 빠른 주기는 10분 단위로 실시간 집계는 아니었습니다. 딜리셔스의 광고는 RTB (Real Time Bidding) 형태로 제공하는데, 실시간으로 처리되는 광고와 다르게 ‘신상애드’의 데이터는 10분마다 갱신되고 있었기 때문에, 고객들은 물론 딜리셔스 내부에서도 실시간 데이터 처리에 대한 니즈는 점점 커져 실시간 집계라는 과제를 고민하게 되었습니다.
두번째 문제는 ‘신상애드’에서 제공되는 데이터가 ‘데이터 마트’라는 것이었습니다. ‘신상애드’ 메트릭 지표를 만들기 위해서는 고객의 행동 데이터와 OLTP데이터를 조합해야 합니다. 데이터 마트로 미리 필요한 데이터를 만들어 두지 않는 경우 OLTP DB의 특성상 대량의 데이터 집계시 속도가 나지 않아 채택한 방법이었지만, 새로운 광고 상품이 생성되거나 변경될때마다 데이터 마트 추가 작업이 필요한 문제가 있었고, 데이터 마트의 관리 포인트는 추가되는 데이터 마트의 수만큼 증가하는 것 또한 문제가 되었습니다.
NARA 프로젝트
Nara 프로젝트는 Non-Aggregation된 데이터를 사용하여 실시간 집계 및 분석할 수 있는 시스템을 구축하는 목적으로 시작되었습니다.
데이터가 수집되는 즉시 Consume되어 Non-Aggregation DB로 적재되며 별도의 가공처리 없이 수집된 데이터 그대로를 사용하여 집계 및 분석을 할 수 있습니다. ‘신상애드’ 페이지에서 메트릭 데이터를 요청하면 Non-Aggregation DB에서 바로 쿼리해서 결과값을 내려주기 때문에 데이터 마트와 같은 별도의 집계가 필요없는 실시간성이 보장됩니다.
NARA Architecture
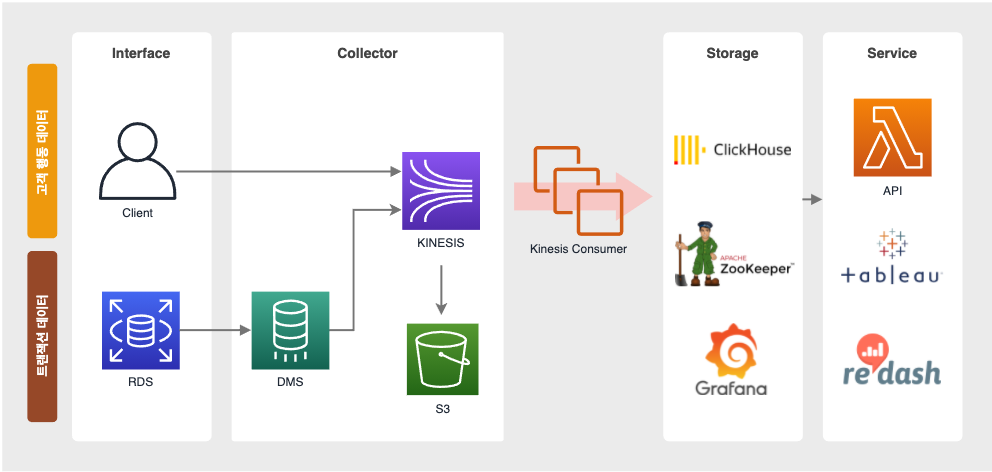
Kinesis로 수집된 고객 행동 데이터와 OLTP 데이터는 Clickhouse DB로 Migration되어 서비스단의 API와 분석을 위한 BI툴에서 사용됩니다.
그럼 NARA 시스템 구성의 주요 특징 4가지를 살펴보겠습니다.
Kinesis Stream
Kinesis Stream은 대용량의 데이터를 수집하고 처리하는데 사용되는 AWS의 실시간 데이터 스트리밍 서비스 입니다.
고객 행동 데이터의 경우 클라이언트에서 직접 Kinesis Stream으로 전송합니다. 그리고 OLTP 데이터는 데이터 집계 뿐만 아니라 서비스 운영에서도 사용되기 때문에 기존과 동일하게 RDB로 적재 되며 아래서 설명할 DMS를 거쳐 Kinesis Stream으로 입수됩니다.
DMS(Database Migration Service)
RDB로 적재된 OLTP 데이터를 Kinesis Stream으로 보내기 위해 AWS의 DMS를 사용합니다. DMS는 DB Migration을 지원해주는 서비스로 Migration의 소스가 되는 DB와 대상이 되는 DB중 하나라도 AWS 서비스 내에 있는 경우 사용 가능합니다.
보통은 백업 DB 같은 복제 용도로 사용 되지만, 저희는 소스가 되는 OLTP DB의 변경사항만 복제하여 Kinesis Stream으로 전송하기 위해 Migration type을 ‘Replicate data changes only’로 설정했습니다. DB의 바이너리 로그에서 변경 사항을 읽고 이 변경 사항을 대상으로 마이그레이션 하기 때문에 소스가 되는 DB에 binlog_format 권한을 추가해 주어야 합니다.
Kinesis Consumer
KCL(Kinesis Client Library)을 활용하여 자체적으로 개발한 Kinesis Consumer를 통해 데이터를 가공하고 Clickhouse DB에 저장합니다.
KCL은 AWS에서 제공하는 Kinesis 데이터 스트림의 데이터를 처리하는 라이브러리로, 대상이 되는 Kinesis Stream의 특정 Shard ID에 해당하는 데이터 레코드를 처리하며 AWS DynamoDB를 사용해 CheckPoint를 관리합니다. CheckPoint를 통해 Kinesis Shard에서 데이터가 얼마나 처리되었는지를 추적할 수 있으며, 이는 Kinesis Consumer가 잠시 중단되었다 재시작되는 경우에도 이미 처리된 레코드 이후의 레코드부터 처리 할 수 있게 해줍니다.
Clickhouse
Yandex에서 만든 OLAP를 위한 컬럼 지향 분산 DBMS으로 다음과 같은 특징이 있습니다.
MergeTree Engine
Table Partition 내부는 Part라는 데이터 단위로 나뉘게 되는데, Insert가 발생하면 새로운 Part가 생성되어 추가되고 뒷단에서 내부적으로 Part들을 병합하며 압축합니다. 그렇기 때문에 Insert의 속도가 빠르며, 데이터 조회시 적은 범위의 데이터를 Scan하게 되므로 조회 속도가 빨라지게 됩니다.
Replication
비동기 Multi-Master 복제를 지원하기 때문에 Replication 된 어느 노드로도 데이터 수집이 가능합니다. 어느 한 노드로 수집된 데이터는 저장 및 압축을 진행하고 나머지 노드로 비동기 복제를 진행할 수 있어 부하 분산과 안정성이 향상됩니다.
Distributed Table
데이터를 여러 Shard에 분산해 저장합니다. 요청이 들어왔을 때 각각의 Shard에서 병렬로 연산하고 연산 결과를 병합하여 Return하기 때문에 쿼리 성능과 데이터 가용성을 향상시킬 수 있습니다.
앞에서 말한대로 컬럼 지향 데이터베이스이며, ANSI SQL이 지원되고 Online query에 적합한 장점 또한 Non-Aggregation 분석 시스템의 구조에 적합하다고 판단했습니다.
이미 삽입된 데이터를 자주 수정하거나 삭제하는 경우에 대해 지원이 제한적인 문제가 있으나, ‘신상애드’에서 필요한 메트릭 데이터는 OLAP성격의 데이터(OLTP 데이터 또한 결제와 낙찰등의 로그 데이터)가 대부분이었기 때문에 스토리지로 Clickhouse를 채택하였습니다.
개선된 점
기존의 Airflow를 사용해 ‘시간 단위 광고상품별 금액 통계’에 대한 데이터 마트 결과를 생성하는데 필요한 시간은 약 2~3분 정도였습니다. 그러나 현재의 NARA 시스템에서는 데이터 마트를 구성하지 않고 Clickhouse에서 바로 쿼리를 통해 실시간 데이터를 API로 내려주므로, 평균 ms 정도로 속도가 대폭 개선되었습니다.
또한 기존 데이터 마트에서는 컬럼 단위 스키마 변경이 있을 경우 데이터 마트를 생성하는 로직을 수정해야 할 필요가 있었으며, 기존에 쌓여있던 마트 데이터를 재구성 해줘야 했습니다. NARA 시스템이 도입된 후, 데이터 마트를 구성할 필요가 없이 Clickhouse에서 바로 결과값을 출력하고 있기 때문에, 앞서 말한 것과 같은 상황에서도 API 변경만 하면 되므로 개발자의 작업 시간이 단축되는 장점이 있었습니다.
앞으로의 과제
Clickhouse DB를 사용하면 별도의 데이터 마트를 구성할 필요가 없지만, 그러기 위해 NARA 시스템을 통한 데이터 적재가 필요합니다. OLAP 목적의 DB이기 때문에 데이터 삭제 및 변경에 관한 처리는 앞으로의 과제입니다. 현재는 삭제 및 변경 관련 Row에 대해서는 별도의 테이블로 관리하고 있으며, 추후 변경 및 삭제된 데이터 처리를 자동화 하는 작업을 진행할 예정입니다.
NARA는 여러 가지 컴포넌트의 조합으로 이루어진 시스템으로, 하나의 컴포넌트라도 장애가 나면 마이그레이션 중에 데이터 누락이 발생할 수 있습니다. 이후 데이터 누락에 대한 Backfill 및 Recovery 기능을 구현하여 안정성 및 어떤 상황에서도 데이터 정합성을 보장할 수 있도록 할 계획을 갖고 있습니다.
또한 앞서 얘기한 KCL에서는 중복된 레코드 처리가 발생할 수 있습니다.(참고) 실제로 운영 중에 이 현상이 확인되었으며, 현재는 수동으로 따로 처리해 주고 있지만, 근본적으로는 중복 로그 제거 기능의 추가 구현이 필요합니다.
마치며
현재는 많은 테스트를 거쳐 NARA 시스템이 배포되었지만, Clickhouse 운영이 처음이고 참고할 레퍼런스가 많이 부족한 오픈소스이기 때문에 이런 저런 시행착오를 겪고 있습니다. 그럼에도 Clickhouse는 기존 데이터 집계 방식의 많은 문제점을 해결하고 성능 또한 우수하다는 분명한 이점을 가지고 있어, 점차 운영 경험을 쌓으면서 빠르고 안정적인 데이터 플랫폼으로 기능할 것을 기대합니다.

이유진
딜리셔스 데이터 엔지니어
"ec9db4ec9ca0eca78420ecb29cec9eac"