배경
왜 해당 논문을 리뷰하는가?
딜리셔스 개발팀의 AI 파트에서는 사용자의 편의성을 높이기 위한 기능의 베이스로 사용되는 머신러닝/딥러닝 모델 만들기를 목표로 합니다. 특히 딜리셔스의 메인 플랫폼인 신상마켓의 검색 기능을 어떻게 하면 더 개선시킬 수 있을지 고민을 많이 하고 있습니다. 검색은 주로 상품이름을 기반으로 검색을 수행합니다. 예를 들어, 신상마켓 어플에서 “무지 카라티”를 검색하면 아래와 같이 결과가 나옵니다. (신상마켓 서비스 특성상 이미지는 블러 처리 했습니다.)

저희 파트는 여기서 한단계 더 나아가 각 상품별 이미지를 설명하는 키워드를 추출하고 싶었습니다. 이미지를 보고 해당 이미지를 언어로 설명하는 작업을 Image Captioning 이라고 부릅니다. 이러한 모델을 만들 수 있다면 신상마켓 검색 서비스의 성능과 편의성을 개선할 수 있을 것입니다.
그러던 도중 CLIP이라는 이름의 방법론을 소개하는 논문 및 블로그 글을 보게 되었습니다. 제가 기존에 알고 있던 Image Captioning 모델 학습 방법과는 조금 달랐는데 직관적인 학습법에 비해 괜찮은 성능 및 효율성을 보여준 방법론이라 인상 깊었습니다. 정리하면서 이해해보고, 추후에 저희 서비스에도 사용할 수 있는지 여부를 검토하기위해 해당 논문을 리뷰하는 형태로 본 글을 게시하게 되었습니다.
CLIP 목적
CLIP의 개발 목적은 더 나은 일반화 성능을 갖는 pre-trained 모델을 만드는데 있습니다. 기존 Vision의 pre-training 문제는 분류문제였습니다. 이를 위해 ImageNet이나 JFT 데이터셋 등 큰 규모의 데이터셋을 활용해 큰 규모의 모델을 미리 학습시켰습니다. 그러나 분류 문제만으로는 일반화된 모델을 생성하기 어렵습니다.
기존 분류 모델을 학습시키려면, 정해진 Label에 대해서 다음과 같은 행렬을 만들어서 학습시킵니다. 예를 들어, 정해진 범주가 “개, 고양이, 말, 자동차, 전투기” 라고 가정하면 다음과 같이 표현합니다.
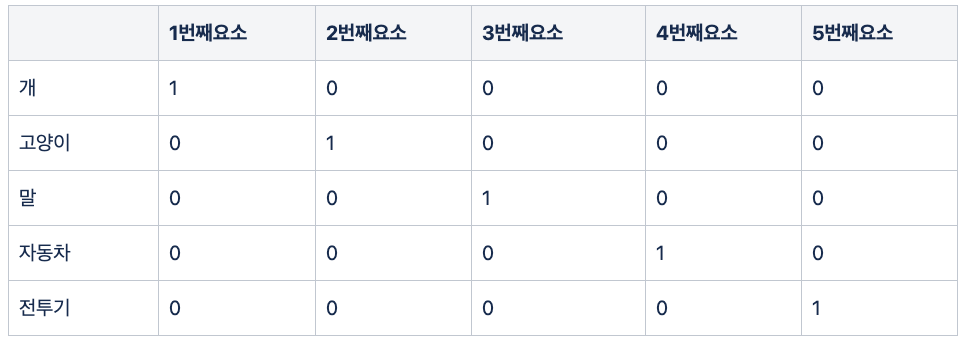
이러한 표현방법을 One-Hot Encoding 이라고합니다. 즉, 하나의 범주를 1과 0으로 표현된 벡터로 바꾸는 방법인데 1이 서로 다른 위치에 있어야 합니다. 그래서 해당 방식의 전제는 “모든 범주는 전부 다르다” 입니다. 이렇게 Label을 표현하여 학습을 시키면 해당 Label의 이미지들끼리는 서로 모이게 됩니다. 분류하는데는 문제가 없을지도 모릅니다. 그러나 이렇게 미리 정해진 Label에 대해서만 학습시키면, 학습 당시 없던 Label의 이미지가 들어왔을때는 제대로 특성을 추출해주지 못할 가능성이 있습니다. 그런 Label의 이미지를 학습시키려면 데이터를 또 추가해서 다시 학습시켜야 합니다. 그래서 이러한 분류문제 대신 Image-Captioning 문제를 푸는 모델을 미리 학습시키자는 연구 분야도 생겼습니다. Label 대신 텍스트를 통해서 더 광범위한 시각적 개념을 학습할 수 있기 때문입니다.
CLIP은 Contrastive Language–Image Pre-training 의 약자입니다. 아마 머신러닝/딥러닝을 공부해보신 분이라면 어느정도 유추가 가능하실겁니다. Contrastive 는 우리말로 번역하면 “대조하는” 이라는 뜻을 가집니다. 그럼 어떤 것들을 서로 대조해보는 걸까요? 이름을 통해 알 수 있듯이 이미지와 자연어(텍스트)를 서로 대조하면서 학습시키는 방법론 입니다. 그럼 여기서 어떻게 이미지와 자연어를 서로 대조하여 학습시키는지 살펴보도록하겠습니다.
어떤 원리로 모델이 학습되는가?
문제 정의
딥러닝 모델 학습은 문제를 정의하는 것으로부터 시작합니다. CLIP은 배경에서 언급한 Image Captioning 문제로 정의합니다. 즉, 하나의 이미지와 그 이미지를 설명하는 텍스트를 매칭시키는 문제를 푸는 모델을 생성합니다.
학습 데이터셋
기본적으로 딥러닝 모델을 생성하기 위해서는 많은 데이터셋이 필요합니다. 기존에는 외부 인력을 통해 학습 데이터를 구축했으며, 이에 따른 리소스는 상당히 많이 쓰입니다. 딥러닝 중 “이미지 분류” 문제에서 자주 사용되는 ImageNet 데이터셋도 인력을 써서 구축된 데이터로 약 2만5천명이 2만2천개의 물체 범주를 labeling 했으며 총 1천4백만장을 작업했다고 알려져 있습니다. OpenAI 에서는 인터넷으로부터 약 4억건의 (이미지, 텍스트) 데이터를 수집하여 모델을 학습시켰습니다. 데이터를 수집하는 방법은 아래와 같이 인터넷 검색창에 텍스트를 입력하면 결과로 나온 이미지들을 사용합니다.
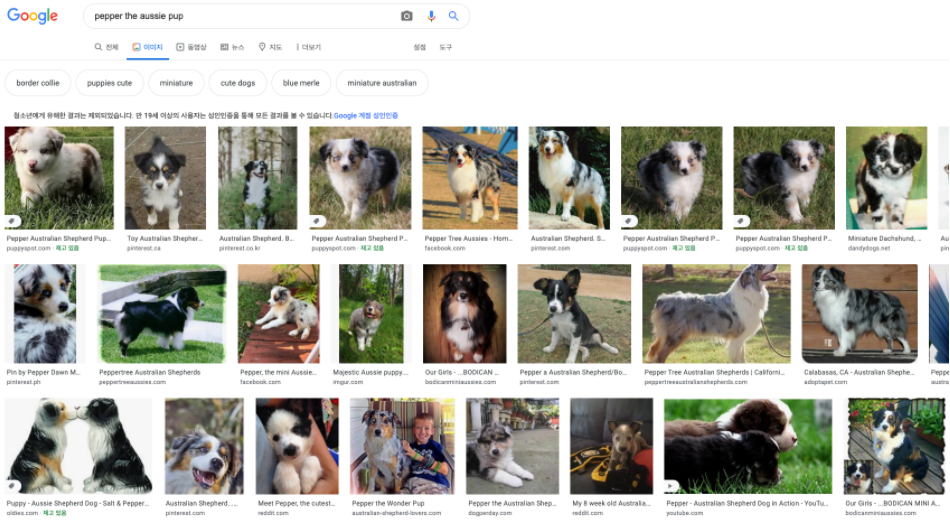
- pepper the aussie pup 이라고 검색하면 위와 같이 관련된 이미지들이 나옵니다.
- 해당 이미지를 설명하는 텍스트가 바로 “pepper the aussie pup” 이 됩니다.
논문에서는 방대한 분야의 검색어 및 이미지를 수집하기 위해 총 50만건의 검색을 수행했고, 이미지의 균형을 대략적으로 맞추기 위해 각 검색어 당 최대 2만개의 이미지를 수집했다고합니다.
모델 학습 및 예측
수집된 데이터를 이용해 아래와 같이 모델을 학습시키고 예측을 수행합니다.
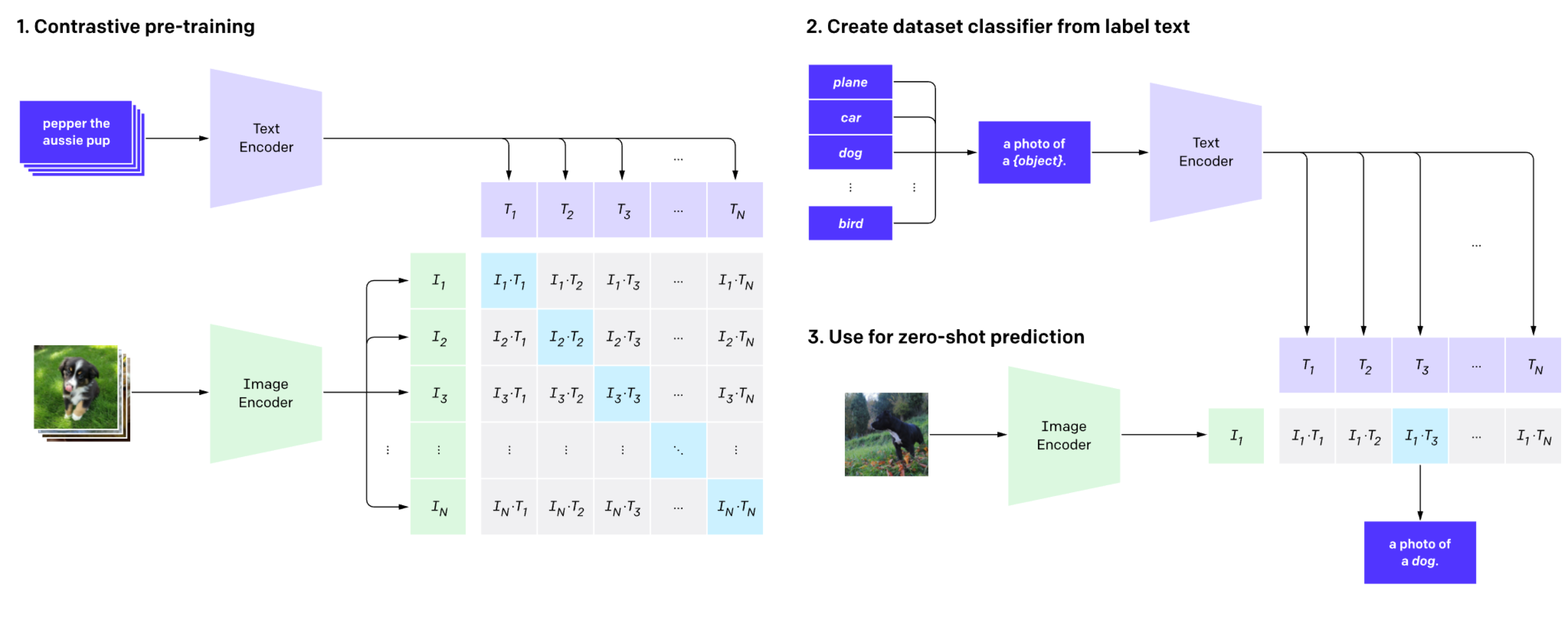
위 그림은 OpenAI에서 작성한 블로그글에 있는 이미지를 캡쳐하여 가져온 것입니다. 하나씩 살펴보겠습니다.
1. Contrastive pre-training
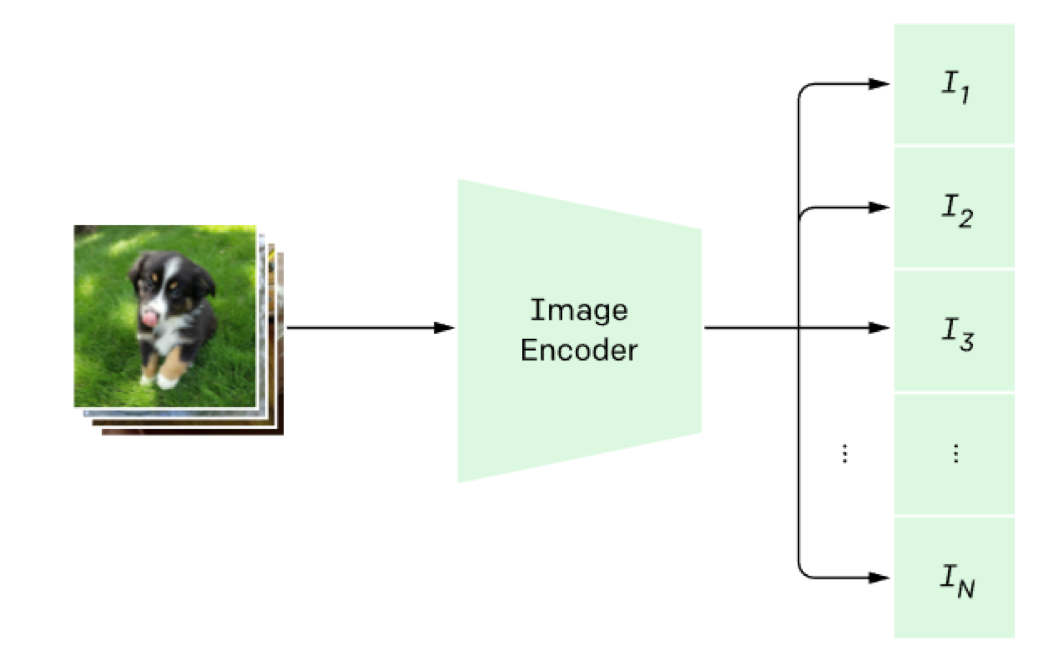
먼저 이미지 하나하나를 Image Encoder에 통과시킵니다. Image Encoder는 이미지를 하나의 벡터값으로 표현합니다. 그림에 있는 N은 배치사이즈를 나타냅니다. 한단계 더 들어가서, 추출된 벡터에 가중치 행렬을 한번 더 곱하고, L2-normalization을 수행하여 각 벡터들을 임베딩(embedding) 합니다.
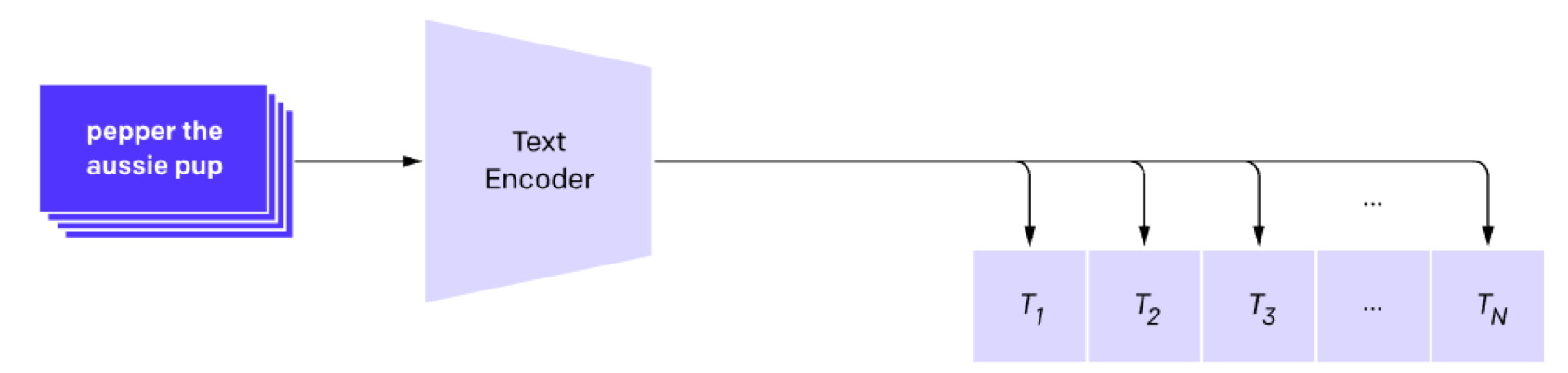
그 다음 각 이미지를 설명하는 텍스트를 Text Encoder에 통과시킵니다. Text Encoder는 텍스트를 하나의 벡터값으로 표현합니다. 이 때 텍스트 토큰 중 문장의 끝을 나타내는 [EOS] 토큰의 벡터값을 텍스트 전체의 벡터로 학습시킵니다. Encoder의 역할은 이미지, 텍스트로부터 각각의 특성벡터를 추출하는 역할을 수행합니다. 이미지와 마찬가지로 추출된 벡터에 가중치 행렬을 한번더 곱하고, L2-normalization을 수행하여 각 벡터들을 임베딩(embedding) 합니다.
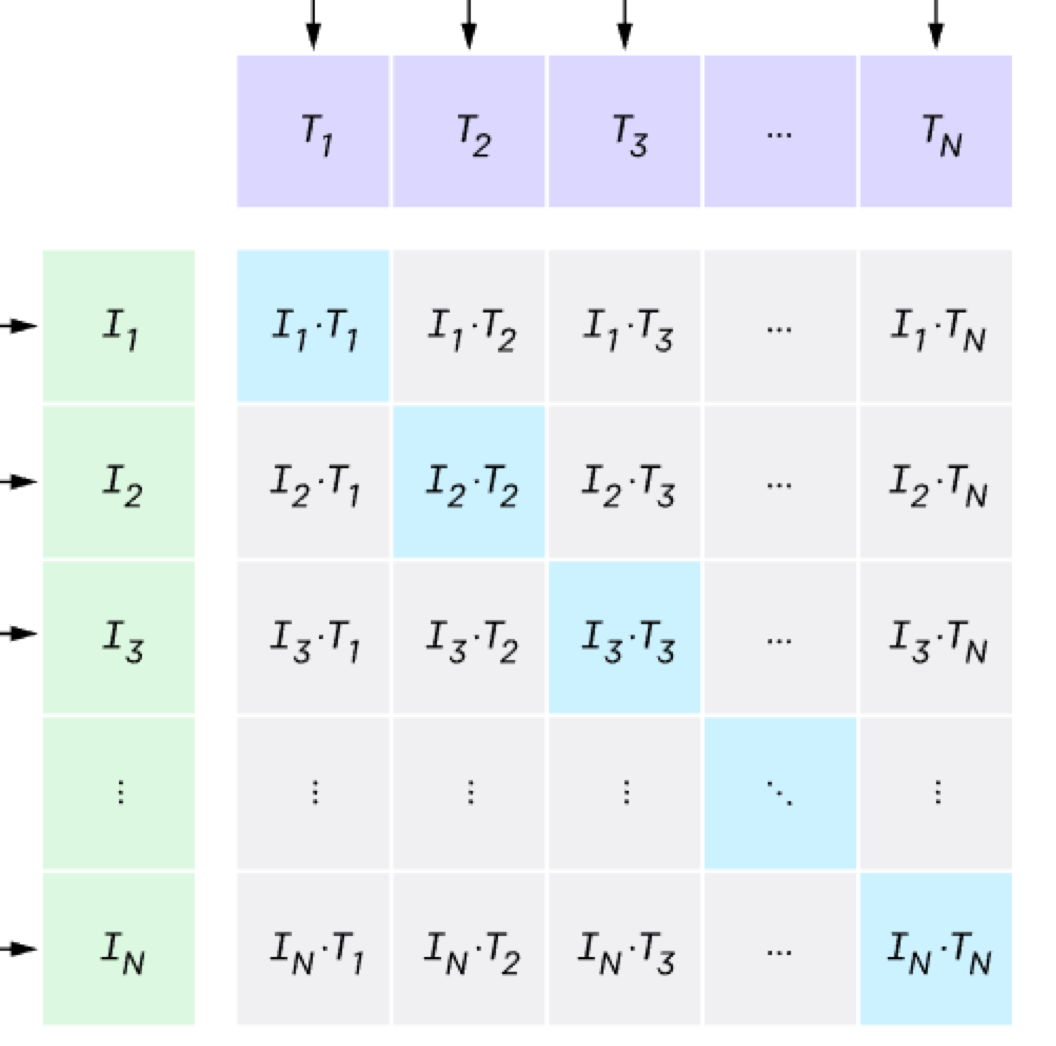
그 다음은 위와 같이 각 이미지와 텍스트 벡터간의 내적을 통해 코사인 유사도를 구합니다. 이전 단계에서 L2-normalization을 수행했기 때문에 단순 내적을 통해 코사인 유사도 값을 구할 수 있습니다.
그러나 여기까지는 모델을 학습시키기 위한 계산과정일 뿐입니다. 학습을 시키려면 정답이 필요합니다. 우리가 여기서 사용할 수 있는 정답은 과연 무엇일까요? 현재 알려진 정보는 첫번째 이미지 벡터를 설명하는 텍스트의 정보는 첫번째 텍스트 벡터에만 있습니다. 다시 말해, 자기 자신을 제외한 나머지 텍스트 혹은 이미지는 서로 다르다는 관계를 가지고 있습니다. 따라서, i번째 이미지와 유사한 텍스트는 오로지 i번째 텍스트 밖에 없습니다. 이는 각 유사도 점수는 1부터 N까지의 숫자들중 하나의 Label을 가진 것으로 해석할 수 있으며, 이를 통해 Cross Entropy loss를 계산할 수 있습니다. 논문에서는 이미지 관점에서의 cross entropy loss와 텍스트 관점에서의 loss값을 계산합니다. 여기서는 하나의 이미지에 대해서 어떻게 loss를 계산하는지 예시를 들어보겠습니다.
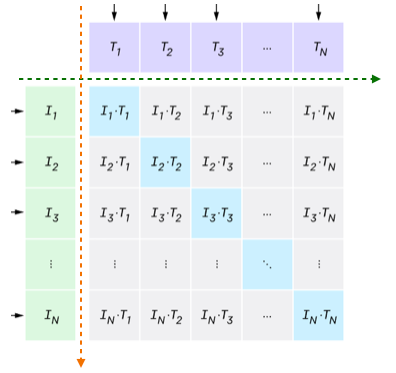
위 그림에서 초록색 화살표 방향으로 loss를 계산하면 이미지 하나하나에 대해서 loss를 계산합니다. 반대로 주황색 화살표 방향으로 loss를 계산하면 텍스트 하나하나에 대해서 loss를 계산합니다. i 번째 이미지의 loss는 다음과 같이 계산합니다.
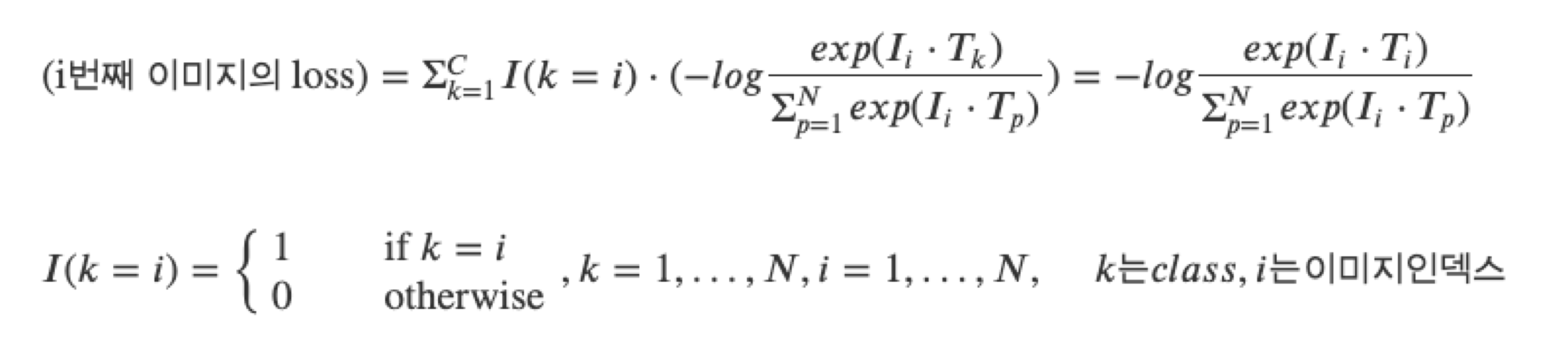
예를 들어, 세번째 이미지의 loss값은 다음과 같습니다.
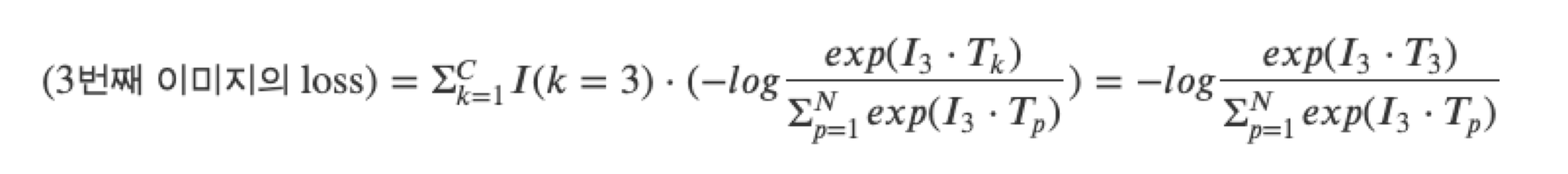
위와 같은 계산 방식으로 첫번째부터 N번째 이미지까지 적용합니다. 이미지 뿐만아니라 텍스트 관점에 대해서도 계산을 진행합니다. 그러면 각각의 loss값들은 N개의 요소를 가지는 벡터가 됩니다. 2개의 벡터를 더한 후 2로 나누어줍니다. 이렇게 해서 구한 loss를 기반으로 모델을 학습시킵니다.
여기까지가 Contrastive pre-training 단계입니다. 정리하자면, 이미지와 텍스트를 컴퓨터가 인식할 수 있게끔 벡터로 변환 후 이미지 벡터와 텍스트 벡터간의 유사도를 계산하여 이 유사도가 커지는 방향으로 학습을 한다고 보시면 됩니다. pre-training이라고 하는 이유는 광범위한 대용량 데이터셋에 대해 “미리” 학습을 시키고, 다른 하위 문제에 적용하겠다는 차원에서 해당 단어가 쓰였다고 보시면 되겠습니다. 이렇게 미리 학습을 수행한 모델은 특정 분야의 데이터셋에 학습한 모델에 비해 일반화를 잘하기 때문입니다. 이런 모델을 특정 하위 문제에 사용하기 위해서는 보통 “Fine-Tuning”이라는 과정을 거칩니다. 이는 특정 문제에서 사용되는 데이터셋에 한번 더 학습시킨다는 뜻입니다. 그런데 해당 논문에서는 “Fine-Tuning” 과정을 거치지 않습니다. 모델 학습은 해당 단계에서 끝납니다.
2. Create dataset classifier from label text
Fine-Tuning 과정을 거치지 않고 Zero-Shot Prediction을 통해 모델의 예측값을 계산합니다. Zero-Shot Prediction은 특정 하위 문제의 데이터셋을 일체 사용하지 않고 pre-training한 모델을 그대로 사용하여 예측값을 계산한다는 의미입니다. 즉, 하위 문제에 대한 데이터셋을 활용해 모델을 업데이트 하지 않습니다.
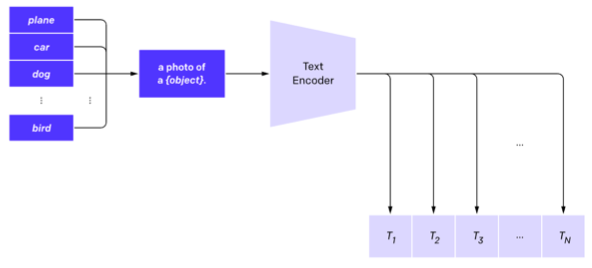
먼저 적용하고자 하는 특정 하위 문제의 데이터셋의 Label을 텍스트로 변환합니다. 예를 들어, 개(Dog)와 고양이(Cat)를 분류하는 문제를 풀고싶다면, “a photo of a Dog”, “a photo of a Cat” 이라는 텍스트를 만듭니다. 이후 Text Encoder에 통과시켜 텍스트 벡터값을 구합니다.
3. Use for zero-shot prediction
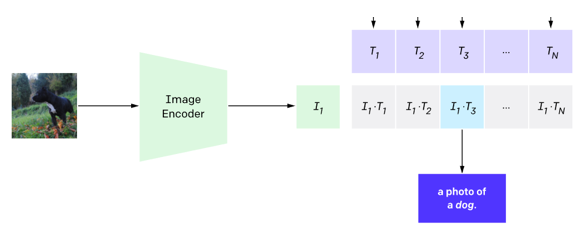
이전 단계에서 나온 텍스트 벡터들과 예측하고 싶은 이미지의 벡터간의 유사도를 계산하여 상대적으로 높은 값을 갖는 텍스트를 선택합니다. 이미지 벡터는 pre-training 시 학습된 Image Encoder를 사용하여 계산합니다.
실험결과
OpenAI에서는 Vision의 다양한 분야에 적용하여 실험을 진행했습니다. 다만 실험한 내용이 너무 많아서 인상적이라고 생각한 부분에 대해서만 리뷰를 하도록 하겠습니다. 상세한 내용이 궁금하시다면 논문을 살펴보시는걸 추천드립니다.
분류 문제의 여러 데이터셋
CLIP이 정말 성능이 좋은 모델인지 확인하기 위한 과정으로 분류 문제의 여러 데이터셋에 성능을 비교했습니다. 특히, Zero-Shot Prediction이 좋은 방식인지 확인해보기 위해 27개의 데이터셋에 ImageNet에 pre-trained ResNet50 모델을 Fine-Tuning 하여 비교했습니다. Fine-Tuning을 하는 방법도 다양한데 여기서는 Output을 출력하는 Top Layer 부분을 데이터셋별로 다르게 학습했습니다. Top Layer 이전 모델의 parameters는 고정시킵니다. 논문에서는 이러한 모델을 Linear Probe라고 합니다.
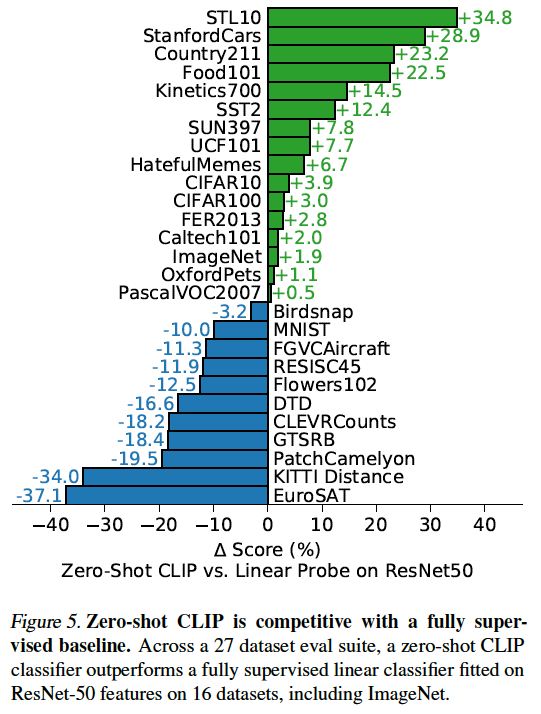
27개중 16개의 데이터셋에서 CLIP의 Zero-Shot Prediction이 Linear Probe 보다 성능이 비교적 좋은 것을 확인할 수 있습니다. 그런데 의외로 MNIST 데이터셋에 대해서는 안좋은 성능을 보였습니다. 이건 좀 충격이긴했는데 논문에서는 pre-training 데이터셋에 MNIST와 유사한 데이터가 거의 없어서 성능이 좋지 않았다고 이야기합니다. 그외 성능이 비교적 좋지 않은 데이터셋들은 상당히 세분화된 분류 문제의 데이터셋(암 진단 혹은 꽃의 종류 구분 등)으로 Zero-Shot 예측은 이런 문제에 약하다는 것을 보여줍니다.
Zero-Shot vs Few-shot linear probes
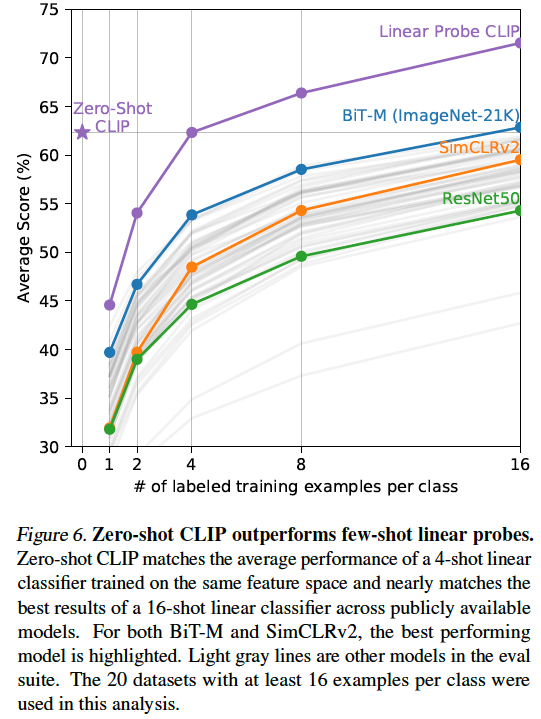
Few-Shot Linear Probes과 성능 비교도 진행했습니다. Few-Shot 의 의미는 각 클래스당 적은 수의 데이터에 대해 Fine-Tuning 하겠다는 의미입니다. 그래프의 x축이 각 클래스당 라벨링된 학습 데이터의 개수를 의미합니다. CLIP이 나오기 전 여러 방법론 중에서 BiT-M(BackBone : ResNet-152x2 / ImageNet-21K 데이터셋으로 학습)이 비교적 좋은 성능을 보였습니다. Zero-Shot CLIP도 성능이 비슷한데, BiT-M은 각 Class당 16개의 데이터셋을 추가로 학습해야 한다는 점에서 추가 학습을 하지 않은 Zero-Shot CLIP이 비교적 효율적인 모델이라고 할 수 있습니다.
상당히 높은 효율성
CLIP은 Image Encoder와 Text Encoder를 학습시켜야합니다. 기존 Image-Captioning 모델에도 Image Encoder와 Text Encoder가 존재하는데, 초기에는 VirTex 라는 방법론과 유사하게 접근했습니다. 그러나 해당 방식은 효율적으로 확장하는데 어려움이 있다고합니다.

x축은 학습에 사용된 이미지 개수를 의미합니다. y축은 ImageNet 데이터셋에 Zero-Shot Prediction을 통한 정확도를 의미합니다. Transformer Language 모델은 이미지에서 텍스트를 예측하는 Transformer 구조 기반의 모델입니다. 논문에서는 Transformer 구조 기반의 Language 모델은 Zero-Shot Prediction의 정확도가 낮음을 실험적으로 보였습니다. 같은 성능에 놓고 비교하면, 해당 모델에 비해서 Bag of Words Prediction의 효율이 비교적 더 좋았습니다. Bag of Words Prediction은 모델을 통해 순서까지 포함한 정확한 단어 예측이 아니라 순서에 상관없이 어떤 단어가 이미지 설명에서 발생하는지 예측하는 방법입니다. 다시 말해, 이미지를 보고 단어의 순서에 상관없이 [“cat”, “my”, “cute”] 이라고 예측한다면, 올바른 예측으로 보겠다는 겁니다. 그리고 해당 논문에서 제시하는 방법론인 CLIP은 Bag of Words Prediction 보다도 상대적으로 더 좋은 효율을 보입니다. 이렇게 효율성이 높아진 이유는 이미지와 텍스트를 연결하는 방식으로 Contrastive Method를 채택했기 때문이라고 이야기합니다.
유연성 및 일반화
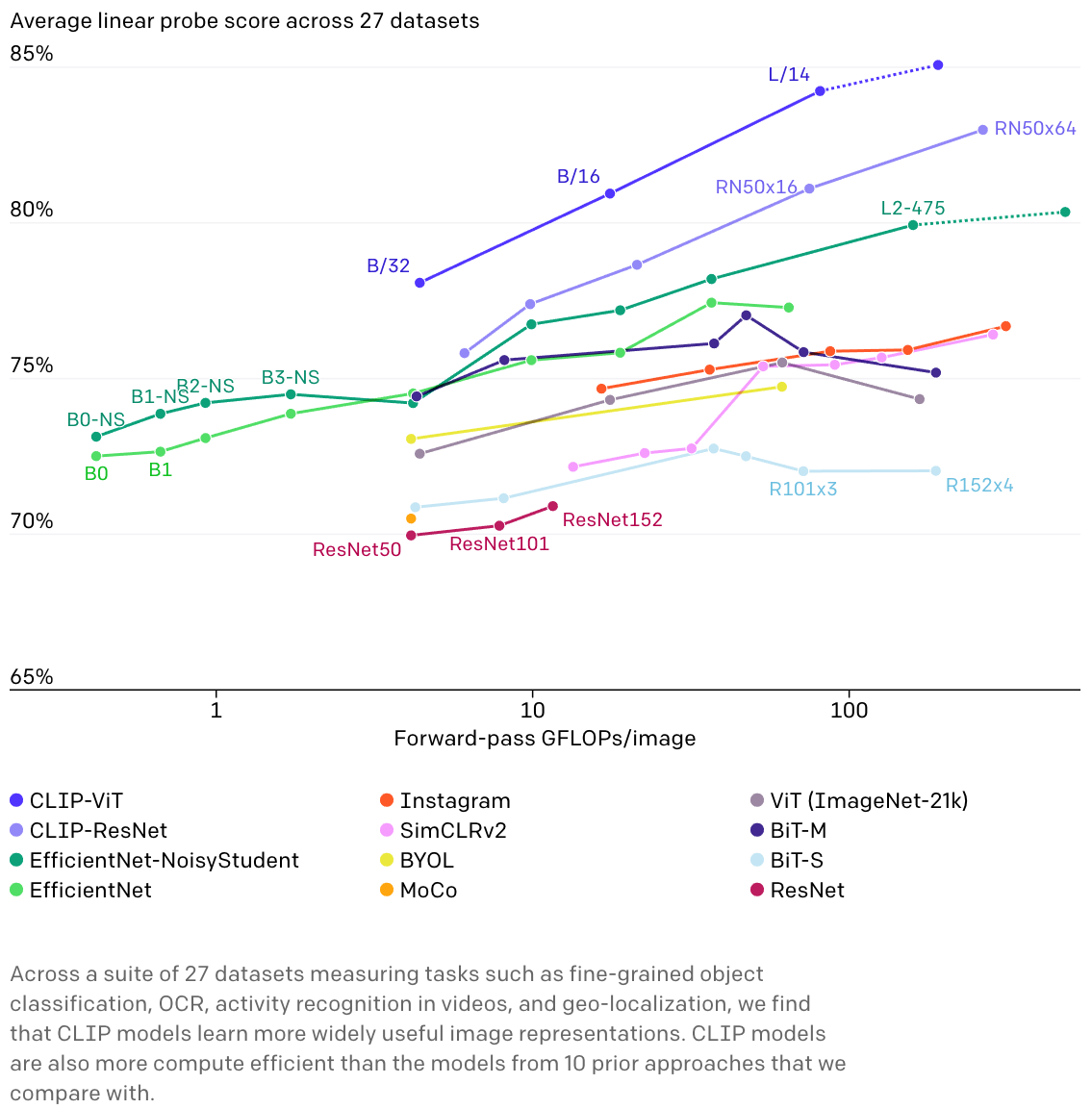
CLIP은 광범위한 이미지들을 직접적으로 설명한 텍스트를 토대로 학습했기 때문에 기존 ImageNet의 pre-trained 모델에 비해 더 유연하고 일반화된 모델이라고 소개합니다. 이를 확인하기 위해 분류 문제 뿐만 아니라 OCR, 비디오에서 Activity 인식 그리고 Geo-Localization 등 다양한 문제를 반영하는 27개의 데이터셋에 측정하여 다음과 같이 시각화를 했습니다. 타 모델에 비해 CLIP-ViT가 성능이 비교적 좋으며, CLIP의 Image Encoder의 Scale이 커질 수록 더 높은 성능을 가집니다.
서비스 기능화
위와 같은 결과를 통해 볼 때 기존 Image-Captioning 모델보다 효율성 측면에서는 우위를 가지고 있는 부분이 있다고 생각합니다. 다만 실제 서비스에서 데이터의 정합성 및 이미지를 설명하는 키워드의 개수의 정의 등에 따라 의미있는 결과를 얻을 수 있을지 추가적인 검증이 필요합니다. 이러한 검증 과정을 거쳐 Multi-Label 분류 모델로 방향을 바꿀 수도 있으며, 이후의 프로젝트 진행에 따라 더 효율적인 방법을 선택할 계획입니다.
참조

배병선
딜리셔스 ML 엔지니어
"에러와 멀어지고 싶다면, 에러와 친해져라"